Графики и ggplot2
30 сентября 2021 г.
1 📊 Столбики
BMI - индекс массы тела,
\[ BMI = \frac{вес}{рост^2} *10000 \]
d <- aggregate(ess7$BMI,
list(country = ess7$cntry),
mean,
na.rm = T)
ggplot(d,
aes(x = country,
y = x
)
)+
geom_col()
1.1 Упорядоченные столбики
# получаем порядок уровней фактора
order.of.countries <- order(d$x)
# используем новый порядок для категорий переменной country
d$country.ord <- factor(d$country,
levels = d$country[order.of.countries]
)
ggplot(d,
aes(
x = country.ord,
y = x))+
geom_col()
1.2 Сгруппированные столбики
d2 <- aggregate(ess7$BMI,
ess7[, c("cntry","rural")],
mean,
na.rm = T)
d2$cntry <- factor(d2$cntry,
levels = d$country[order.of.countries]
)
ggplot(d2, aes(x = cntry,
y = x,
fill = rural))+
geom_col(position = "dodge")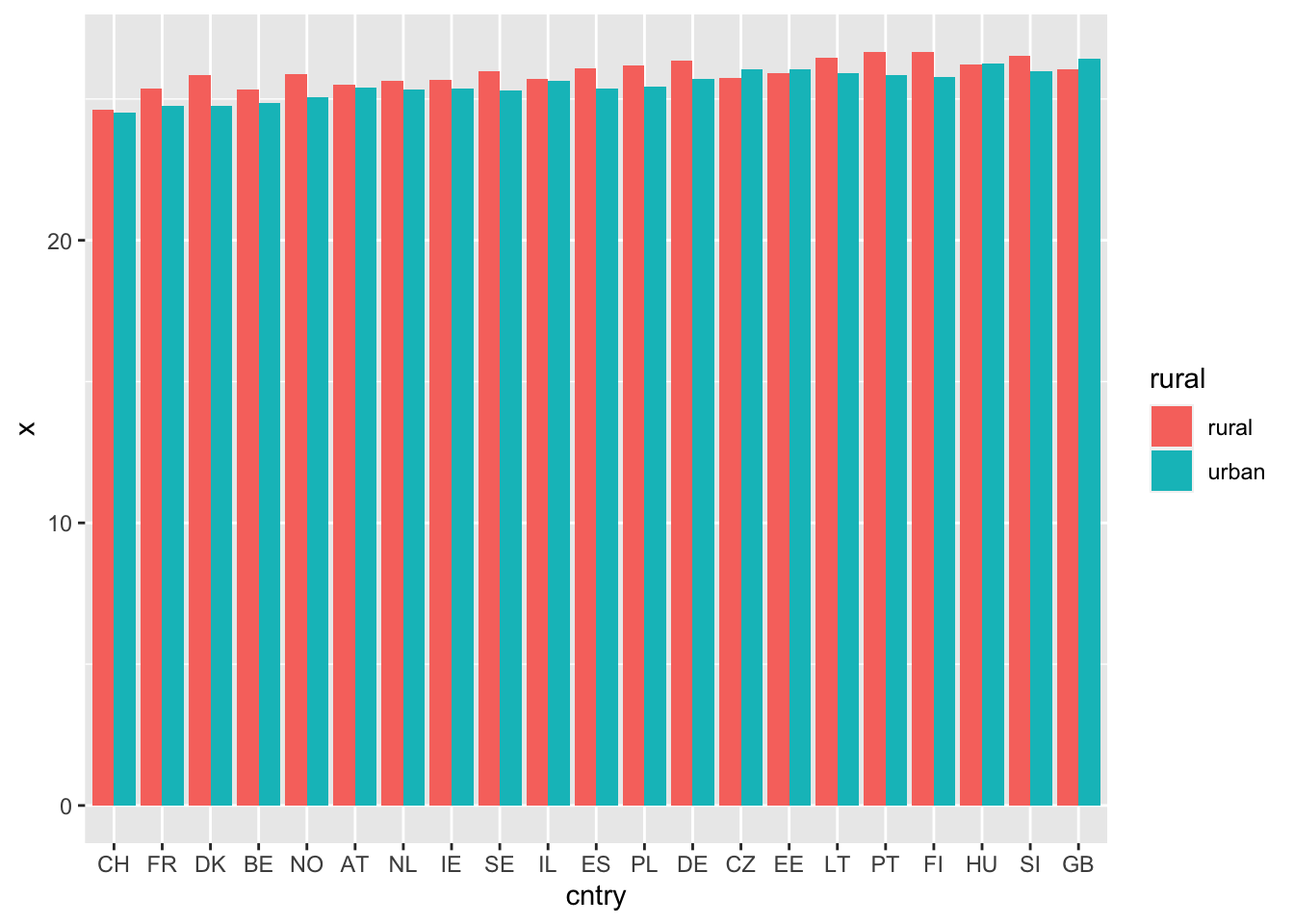
1.3 Перевернем их и добавим подписи
ggplot(d2, aes(x = x, # значения x и y поменялись местами
y = cntry,
fill = rural,
label = round(x), # новая строка
group = rural # новая строка
)
)+
geom_col(position = position_dodge(width = 1)) +
geom_text(size = 2.5,
position = position_dodge(width = 1))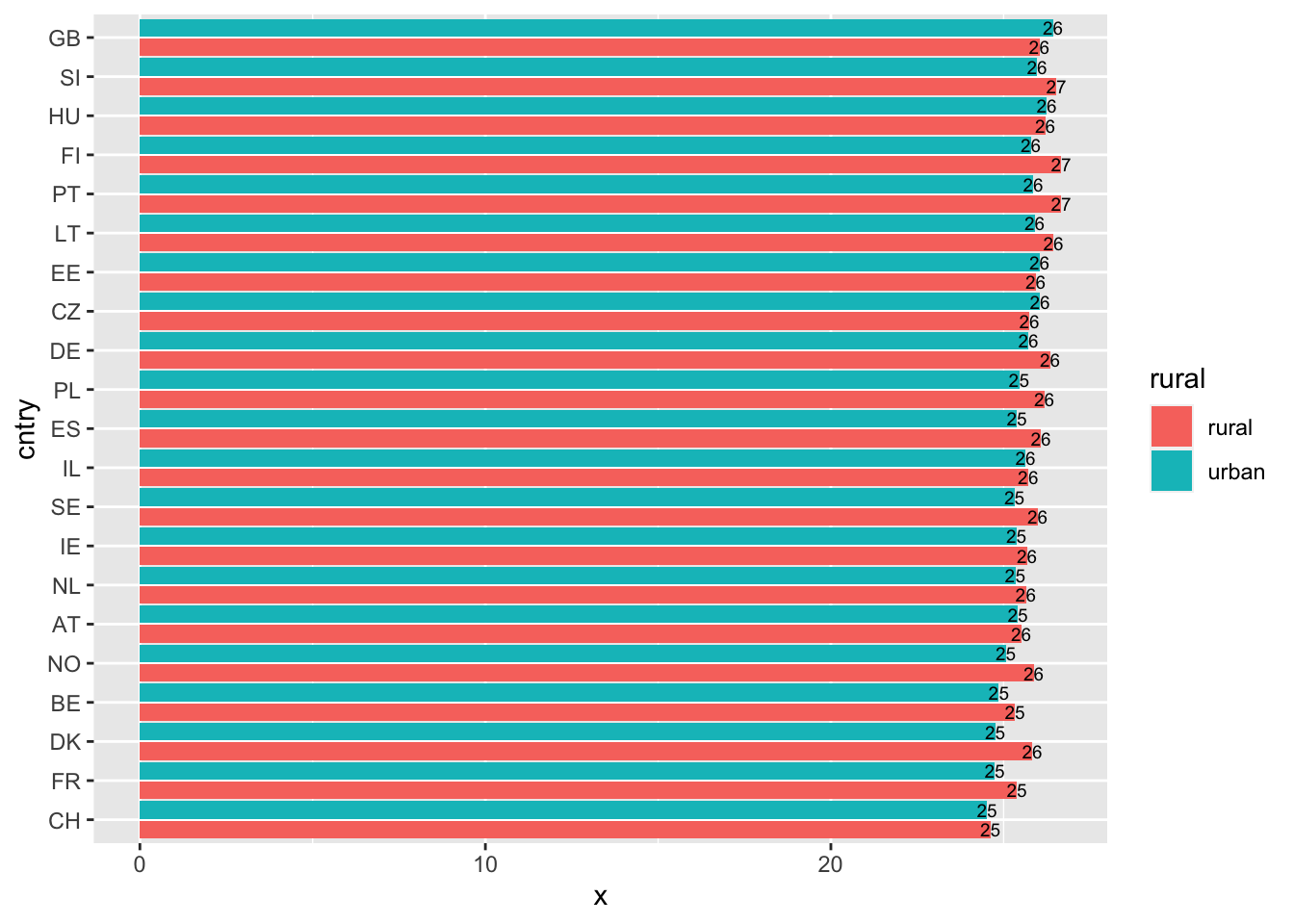
1.4 Сделаем график более читабельным
ggplot(d2, aes(x = x, # значения x и y поменялись местами
y = cntry,
fill = rural,
label = round(x),
group = rural
)
)+
geom_col(position = position_dodge(width = 1)) +
geom_text(size = 2.5,
position = position_dodge(width = 1))+
labs(x = "индекс массы тела",
y = "",
fill = "Тип места проживания")+
theme_minimal()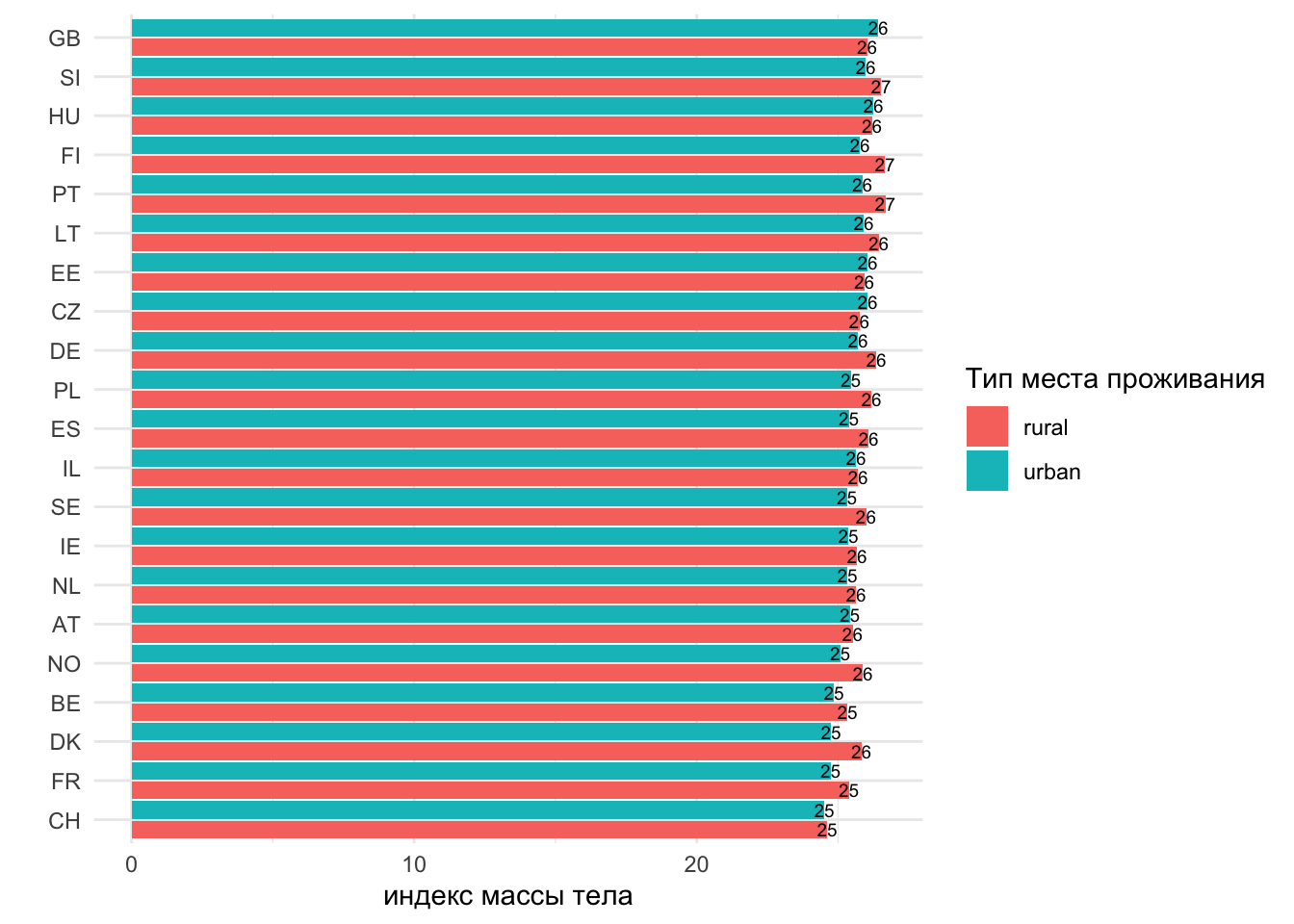
1.5 👉 Самостоятельно - 1
- Вычислите и покажите на столбиковом графике среднее количество употребляемого алкоголя
alcwkdy + alcwkndв каждой из стран ESS. Предварительно добавьте туда непьющих, указав, что они употребляют 0 граммmydata$alcohol[mydata$alcfreq ==7] <- 0. Сделайте колонки синими. Для вычисления средних используйтеaggregate()
ess7$alcohol <- ess7$alcwkdy + ess7$alcwknd
ess7$alcohol[ess7$alcfreq == 7] <- 0
d <- aggregate(ess7$alcohol,
list(country = ess7$cntry),
mean,
na.rm = T)
ggplot(d, aes(x=country, y = x))+
geom_col(fill = "darkblue")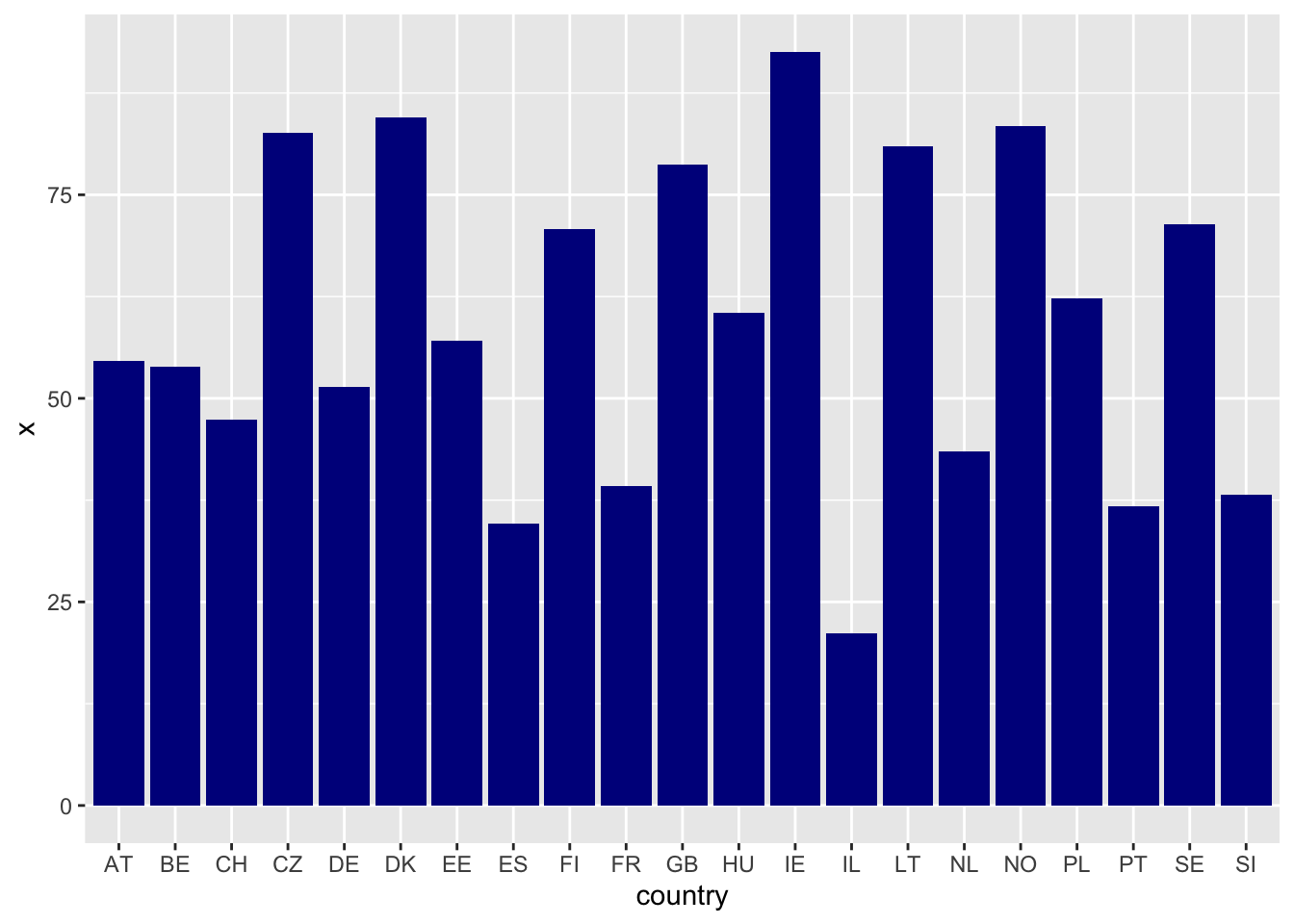
- Отсортируйте колонки по количеству выпиваемого.
d$country.sorted <- factor(d$country,
levels = d$country[order(d$x)])
ggplot(d, aes(x=country.sorted, y = x))+
geom_col(fill = "darkblue")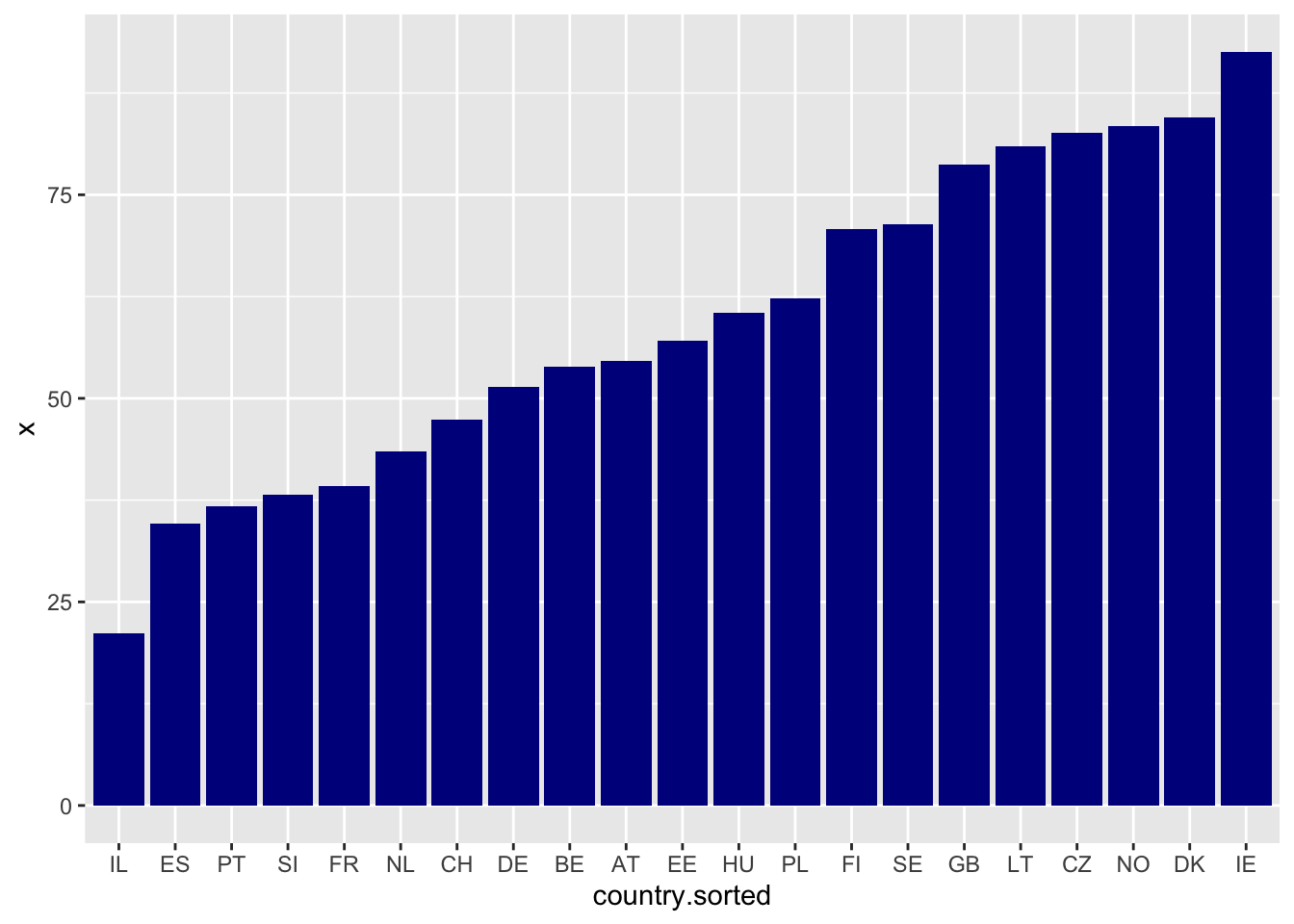
- Добавьте к этому графику подписи со средним количеством выпиваемого, используя
geom_label().
ggplot(d, aes(x=country.sorted, y = x, label = round(x, 1)))+
geom_col(fill = "darkblue")+
geom_label()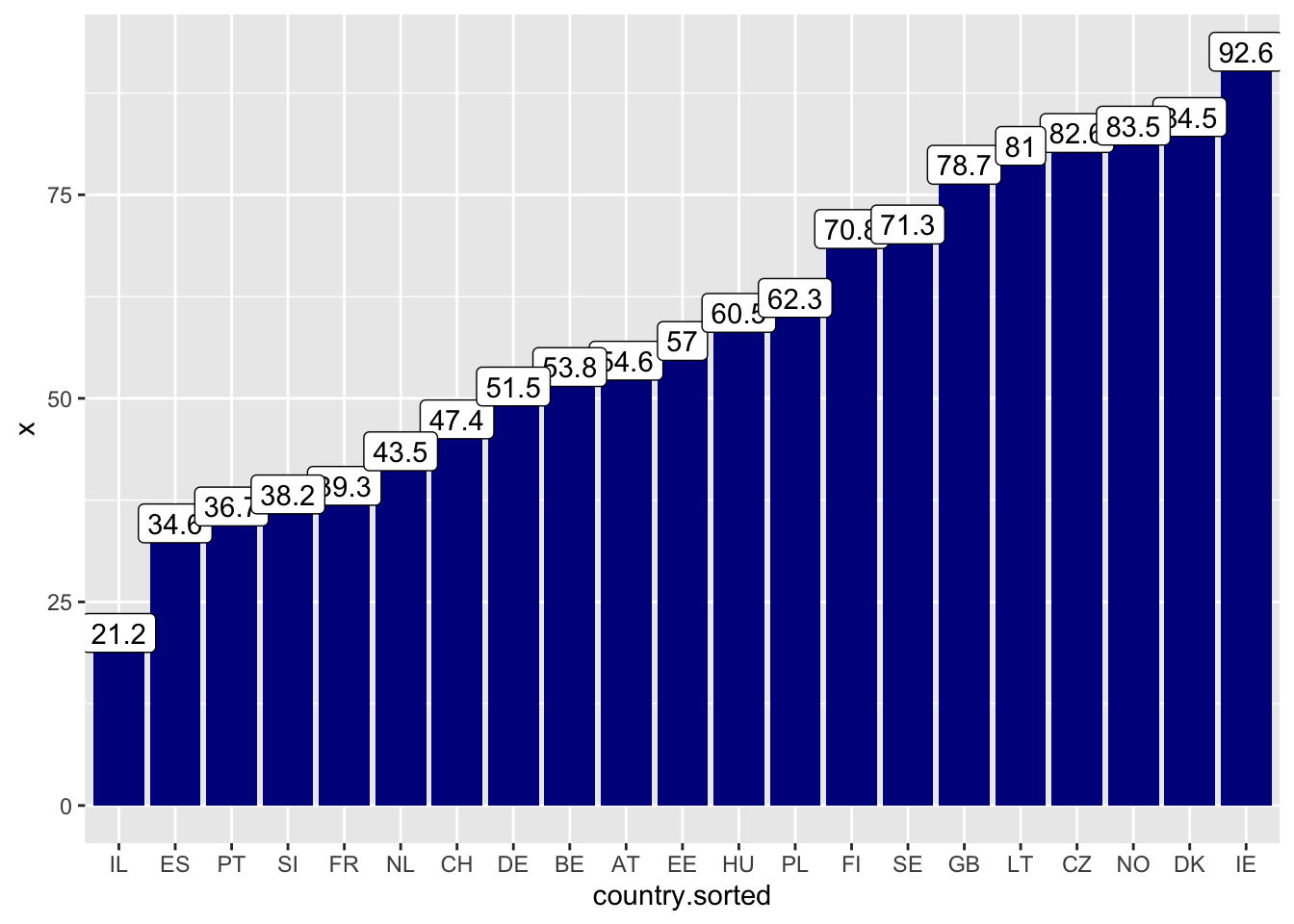
Добавьте к этому графику разбивку по гендеру. Для этого придется заново пересчитать средние, рассчитав их отдельно для каждого гендера и введя гендер как переменную заливки (fill).
Попробуйте упорядочить страны по количеству выпиваемого мужчинами.
d <- aggregate(ess7$alcohol,
list(country = ess7$cntry,
gender = ess7$gender),
mean,
na.rm = T)
d$country.sorted <- factor(d$country,
levels = d$country[order(d$x[d$gender=="Male"])])
ggplot(d, aes(x=country.sorted,
y = x,
label = round(x, 1),
fill = gender
))+
geom_col(position = "dodge")+
geom_label()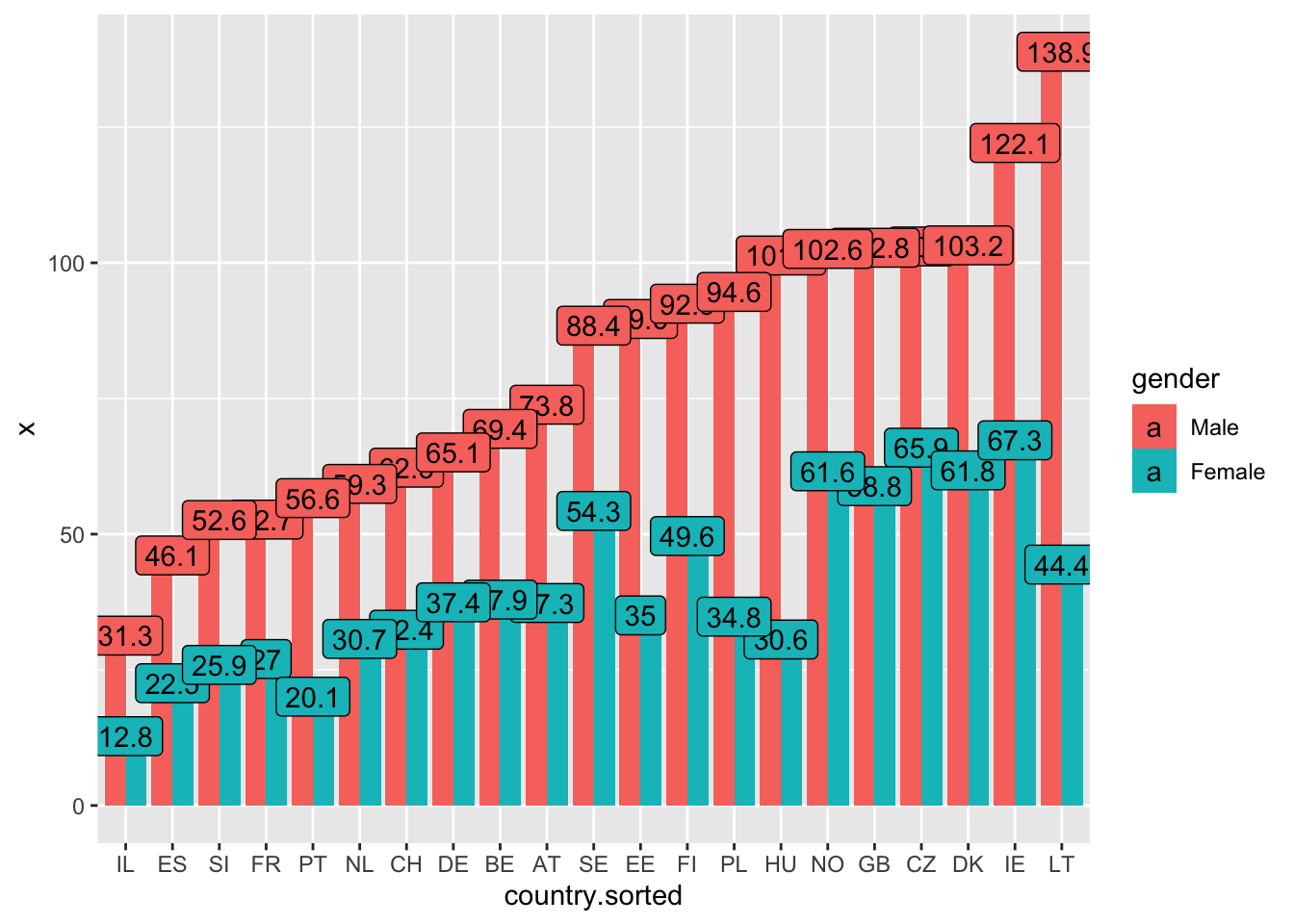
- Разверните это график на 90 градусов
ggplot(d, aes(y=country.sorted,
x = x,
label = round(x, 1),
fill = gender
))+
geom_col(position = "dodge")+
geom_label()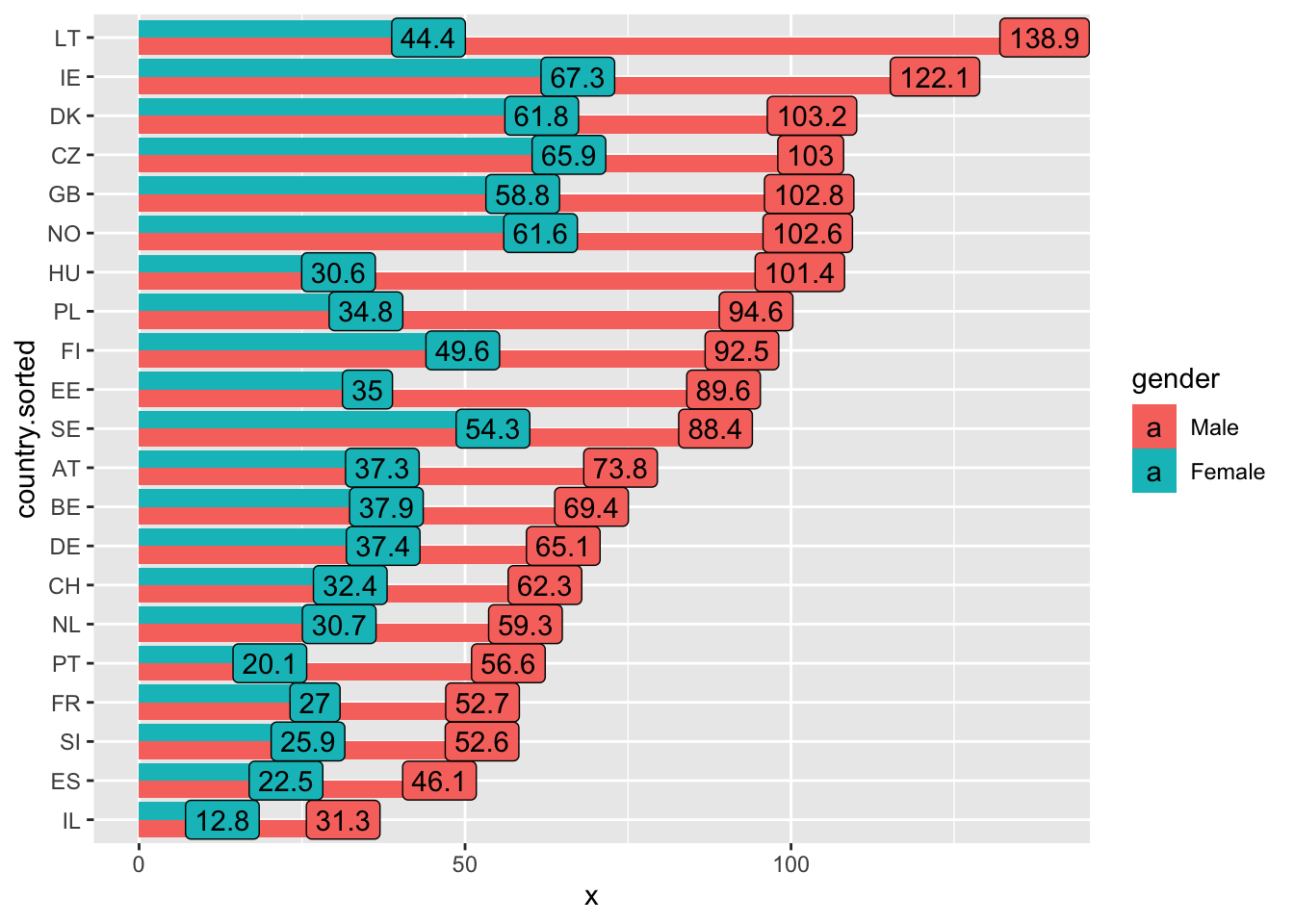
- Поменяйте цвета, чтобы столбики по мужчинам были зеленого, а по женщинам - оранжевого цвета (или любого другого). Используйте
scale_fill_manual()
ggplot(d, aes(y=country.sorted,
x = x,
label = round(x, 1),
fill = gender
))+
geom_col(position = "dodge")+
geom_label()+
scale_fill_manual(values = c("darkgreen", "orange"))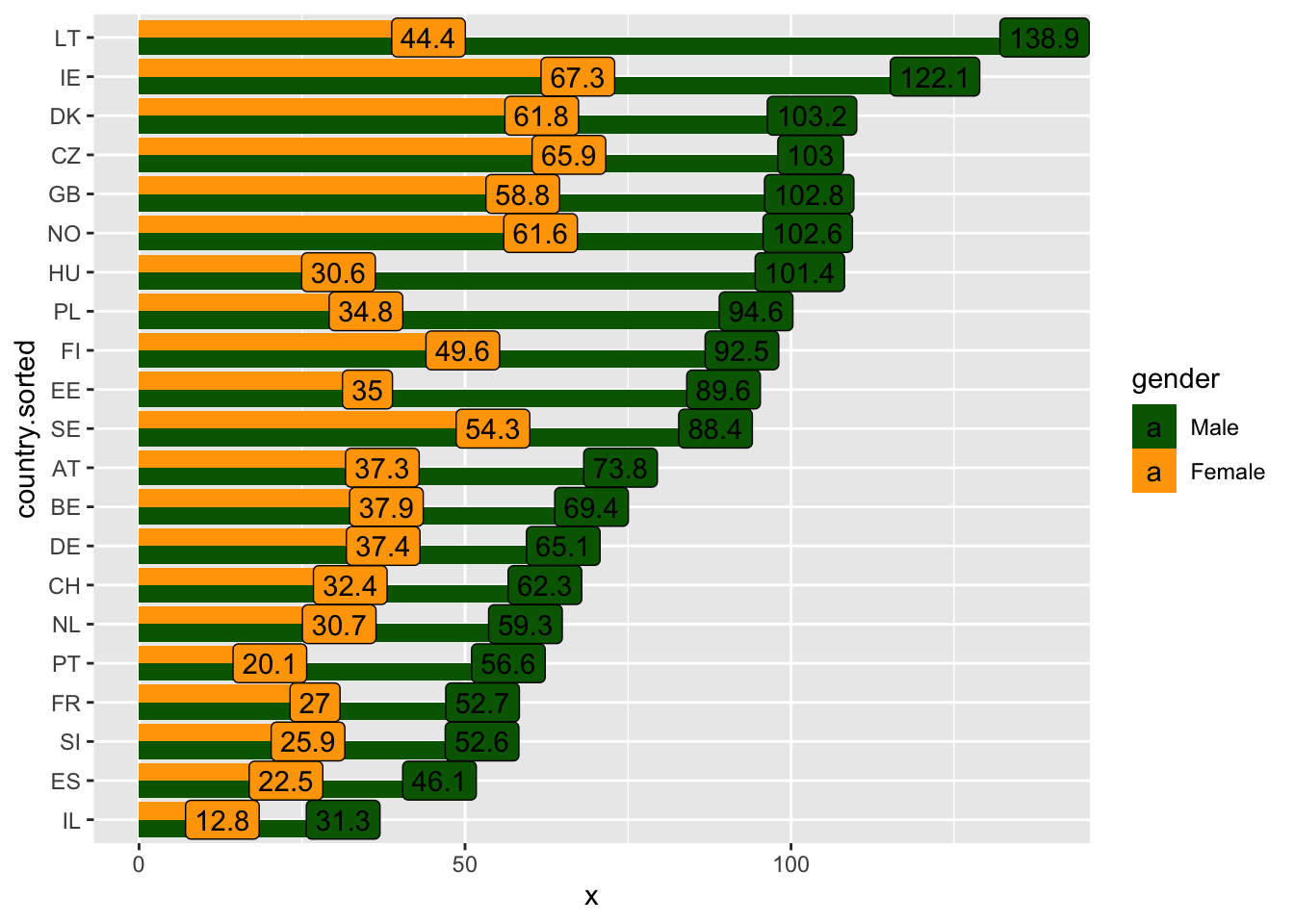
- Добавьте понятные названия осям (
labs()) и примените одну из автоматических тем, например,theme_minimal()
ggplot(d, aes(x = country.sorted,
y = x,
label = round(x, 1),
fill = gender
))+
geom_col(position = "dodge")+
geom_label()+
scale_fill_manual(values = c("darkgreen", "orange"))+
coord_flip()+
theme_minimal()+
labs(y = "Alcohol per week/grams", x = "", fill = "Gender")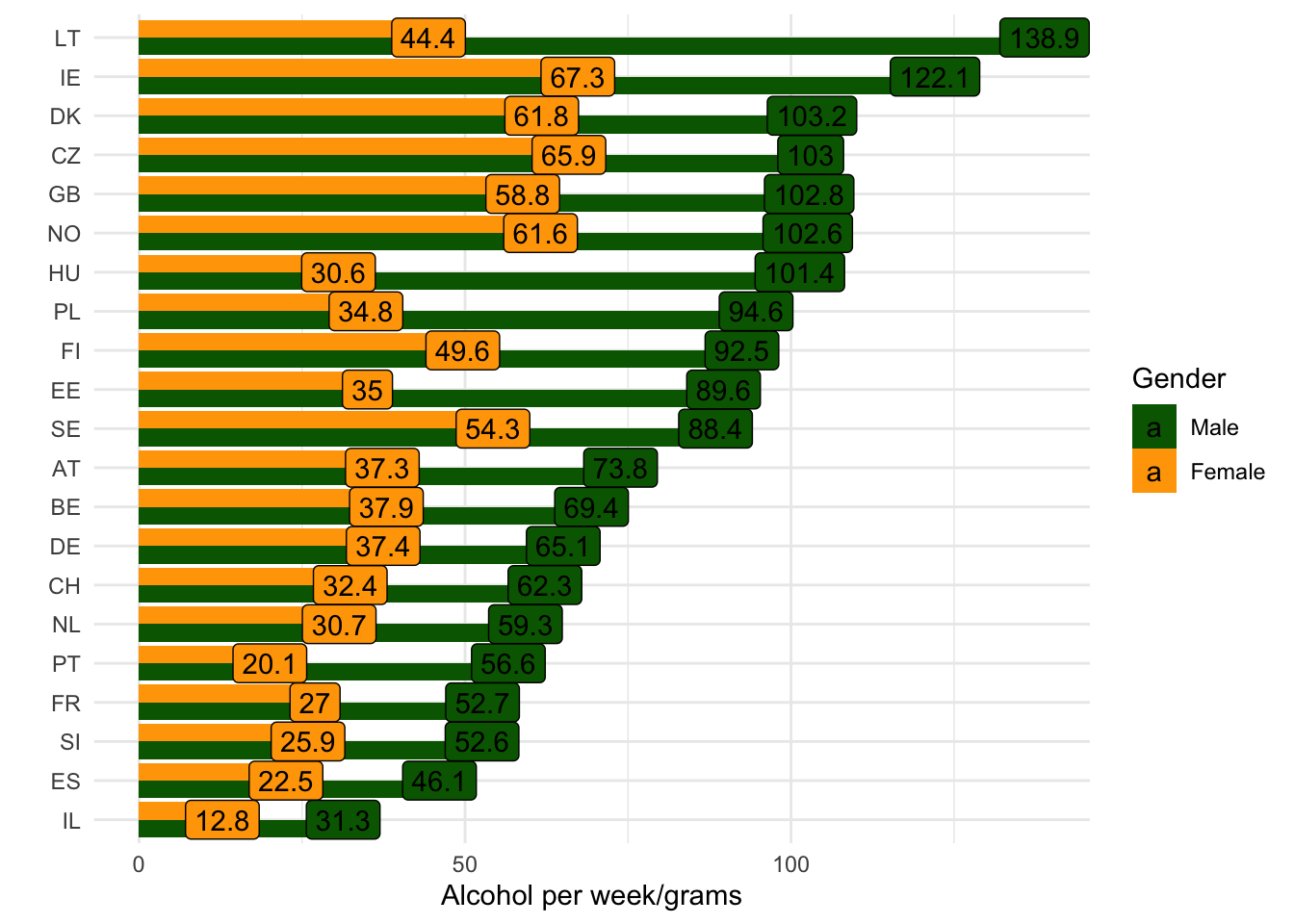
2 📈 Stats ggplot
2.1 Гистрограммы и статс в ggplot2
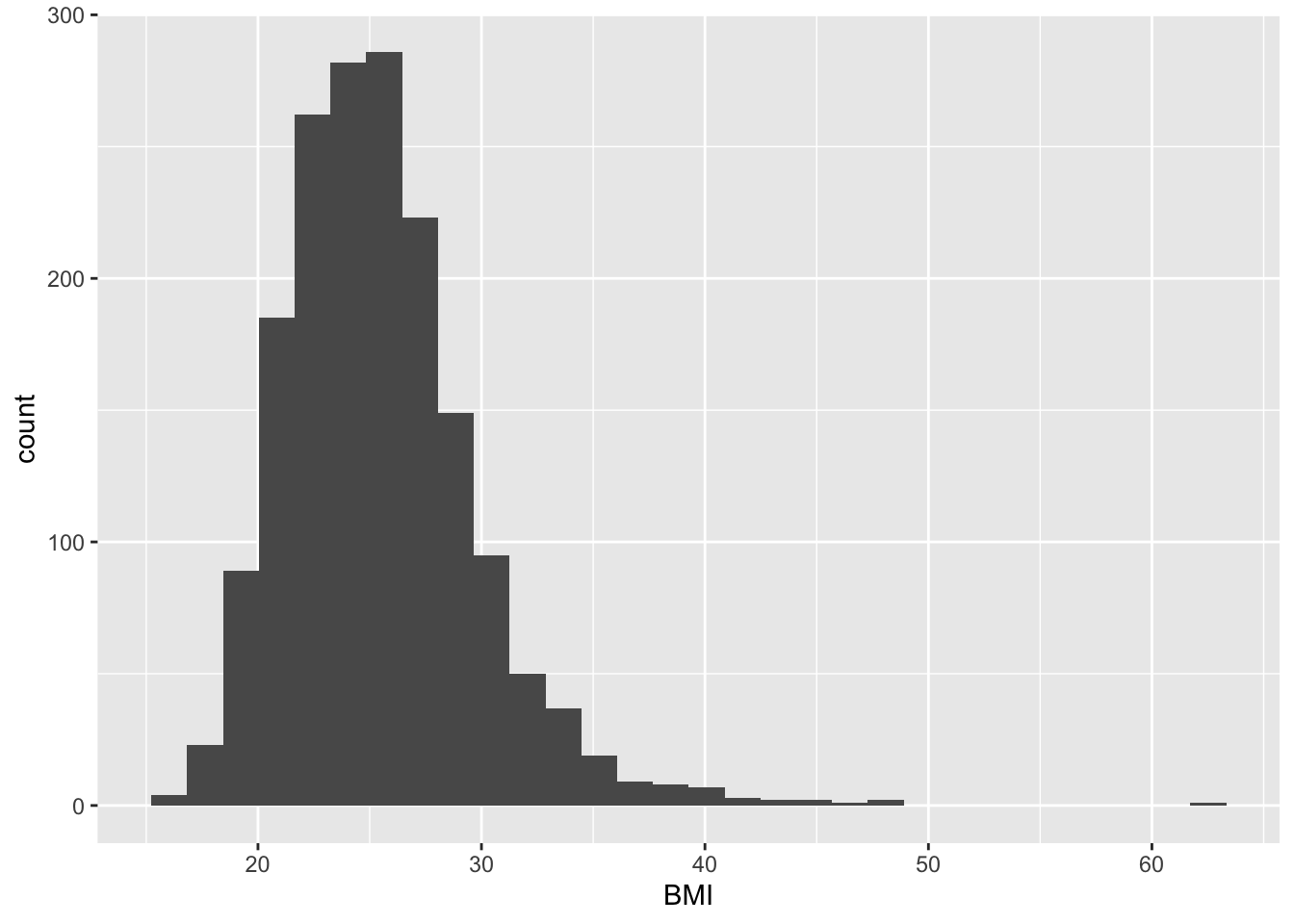
2.1.2 Гистограмма в более гибкой формулировке
Любая функция начинающаяся со stat_ вычисляет данные “на лету”, прямо изнутри ggplot. Он может быть приписан одному из нескольких “геомов”. Он создает внутренние переменные, т.е. результаты расчетов. В случае stat_bin вычисляется переменная stat(count), которая может быть использована в других функциях внутри кода ggplot. К ней можно обращаться изнутри функции через stat(count).
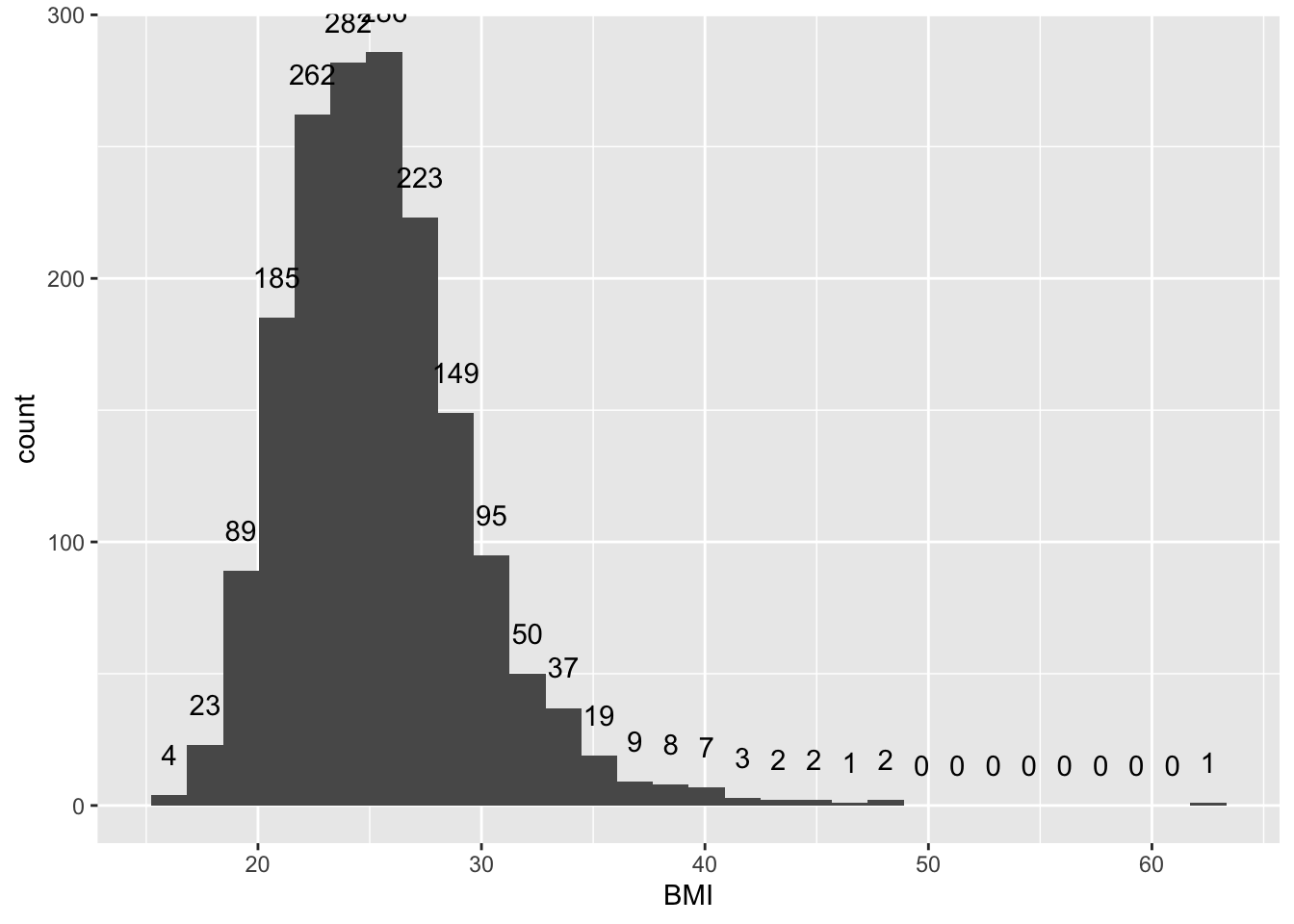
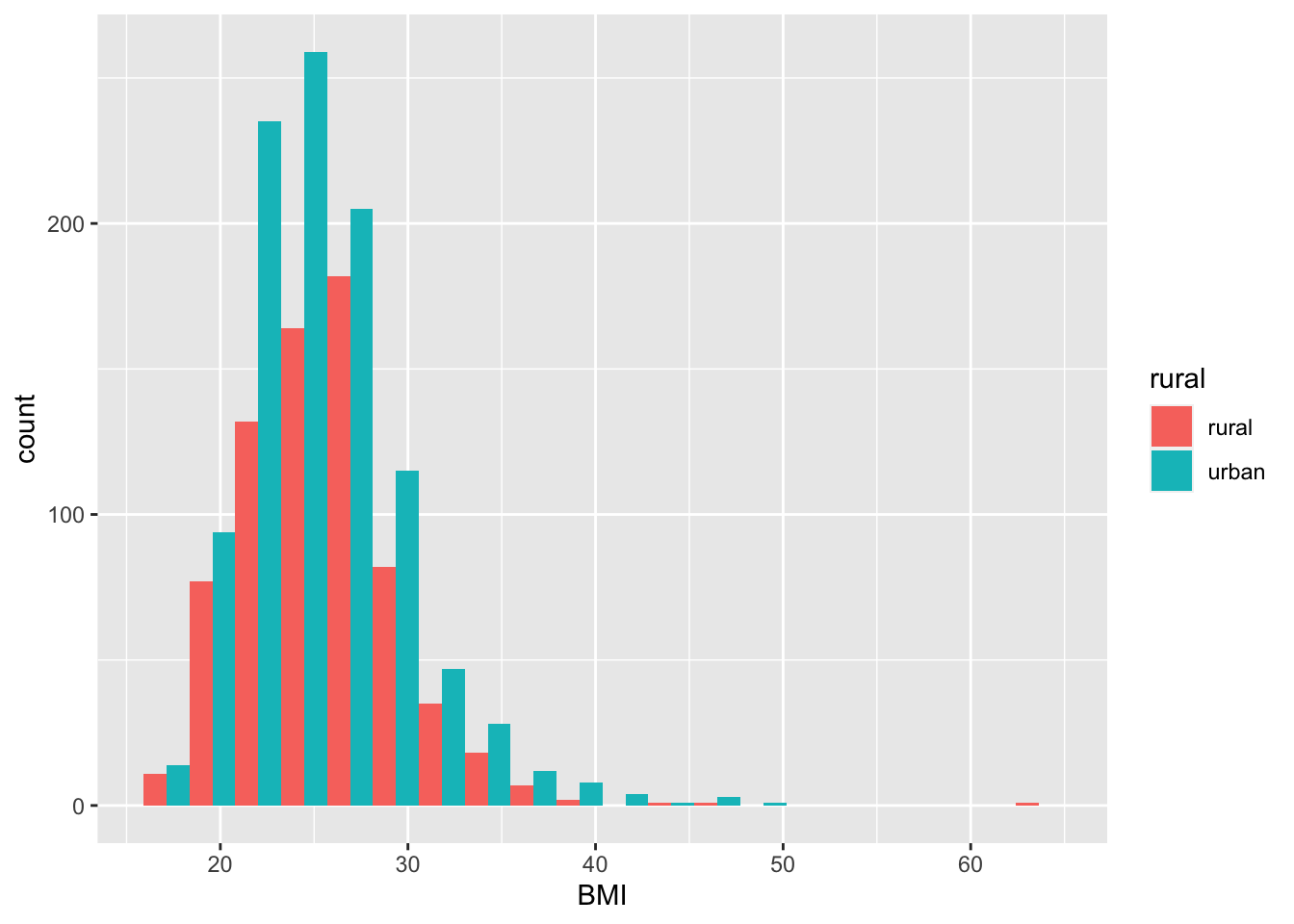
2.1.3 Гистограммы для двух подвыборок
Просто добавим аргумент fill и position.
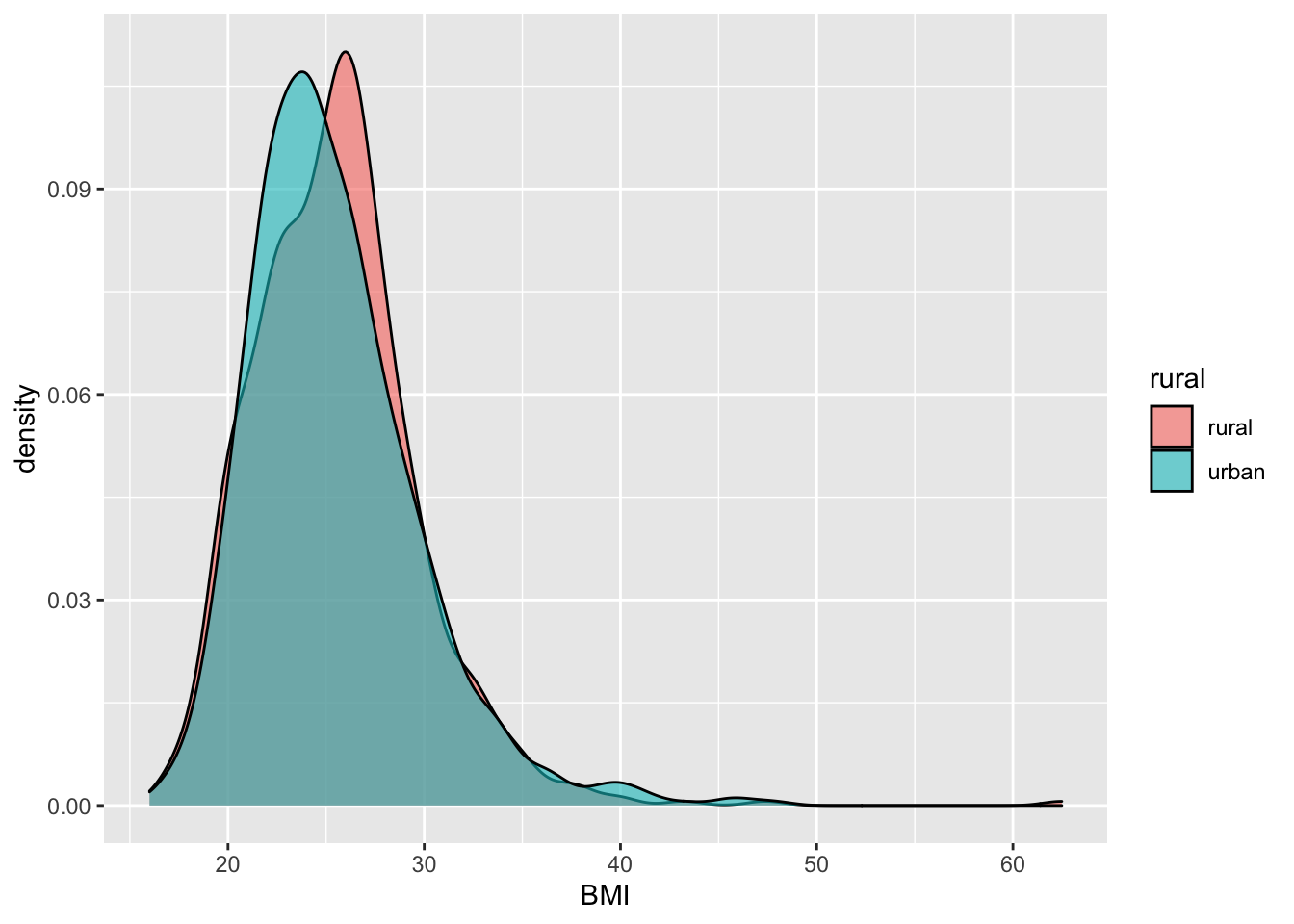
2.2 👉 Самостоятельно - 2
Постройте график плотности переменной alcohol с разбивкой по гендеру
3 Частотные столбики
AT$tvtot <- factor(AT$tvtot)
ggplot(AT, aes(x=tvtot))+
geom_bar()+
geom_label(stat = "count", aes(y = stat(count), label = stat(count)))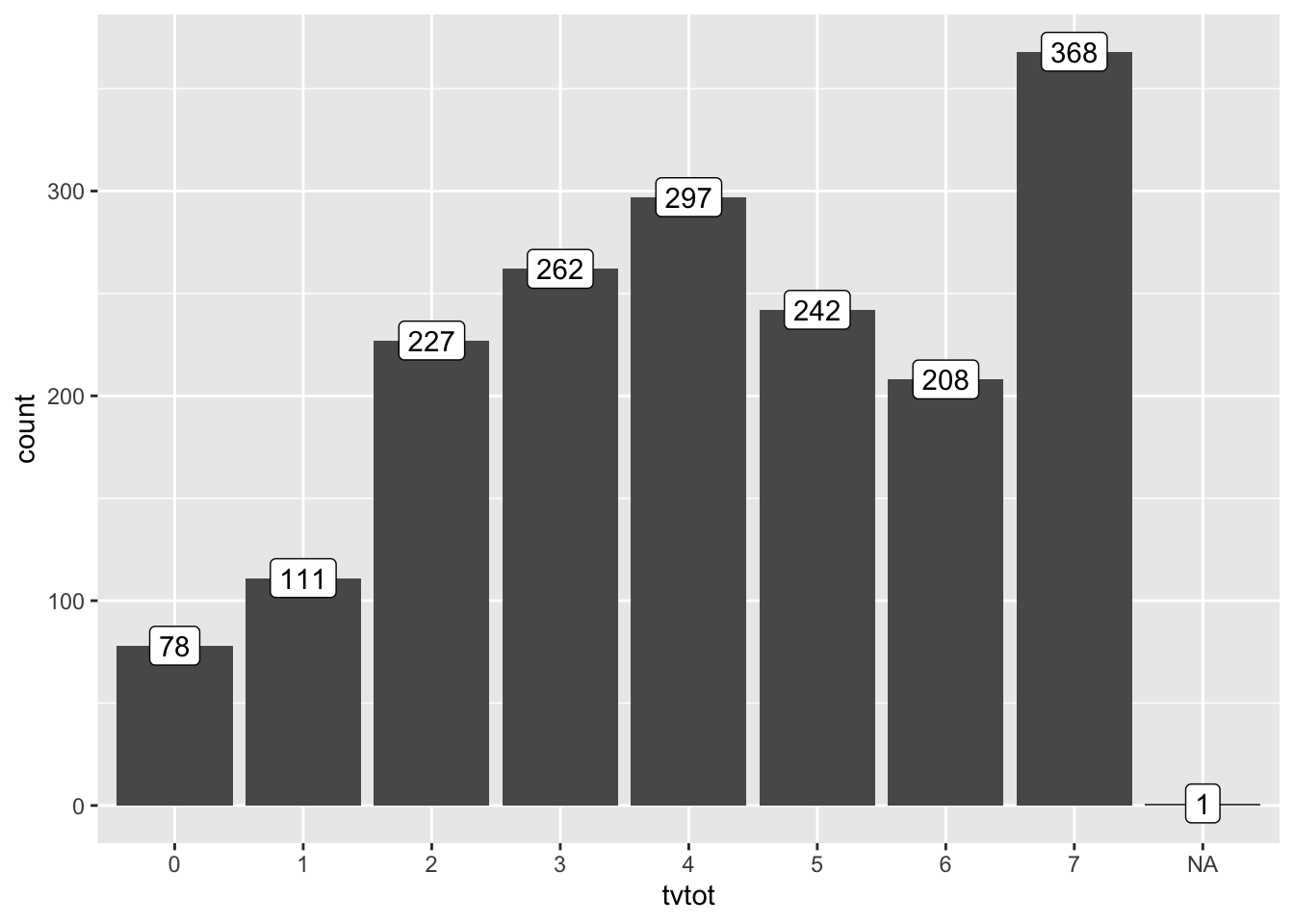
3.1 Сгруппированные столбики
ggplot(AT, aes(tvtot, fill = as.factor(domicil) ))+
geom_bar(position = "fill")+ # fill здесь приводит к тому, что столбики растягиваются по всей оси y, преобразуясь таким образом в проценты
scale_x_discrete(na.translate=F)+
scale_y_continuous(labels = scales::percent) # эта строка просто меняет подписи по оси y на проценты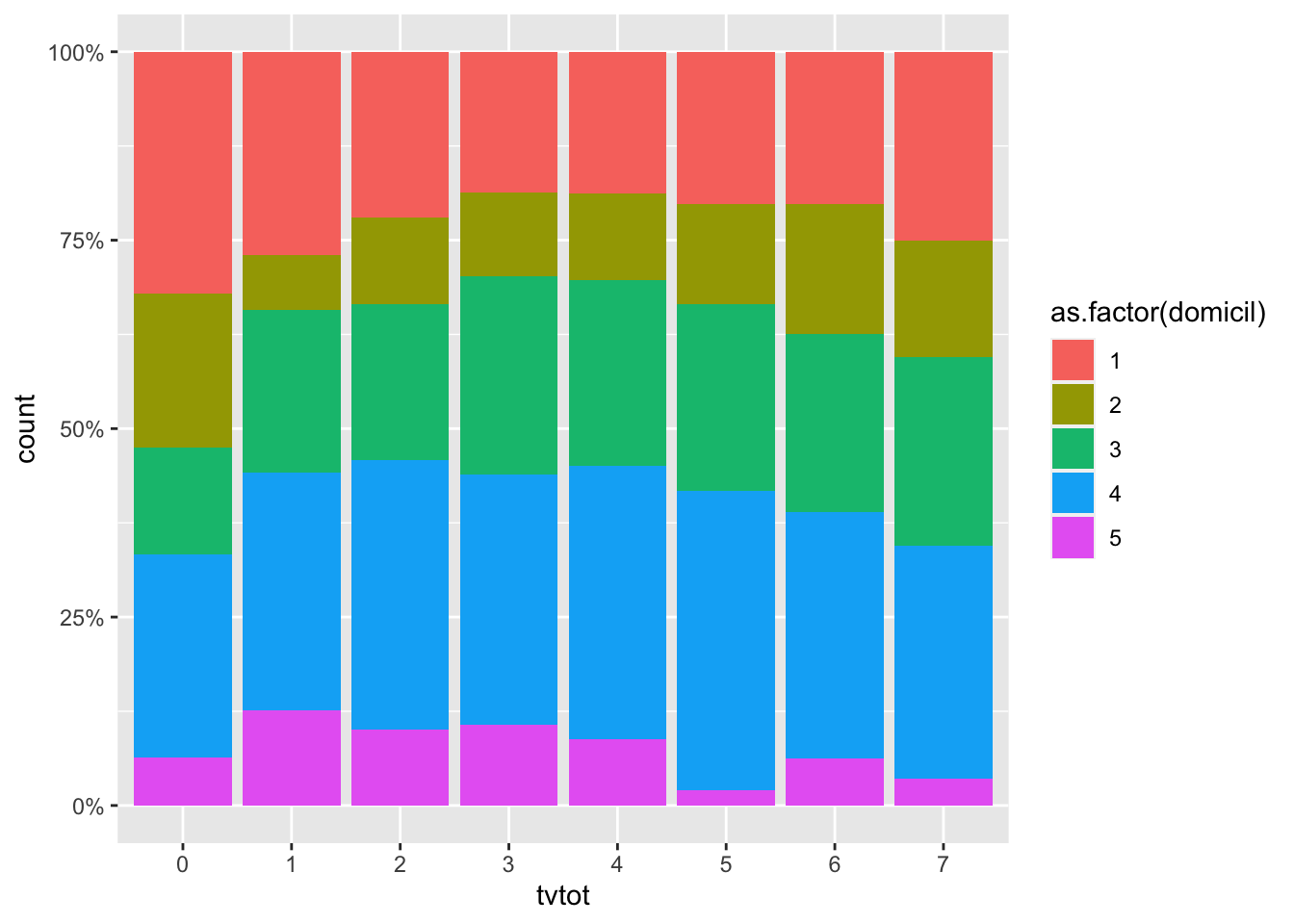
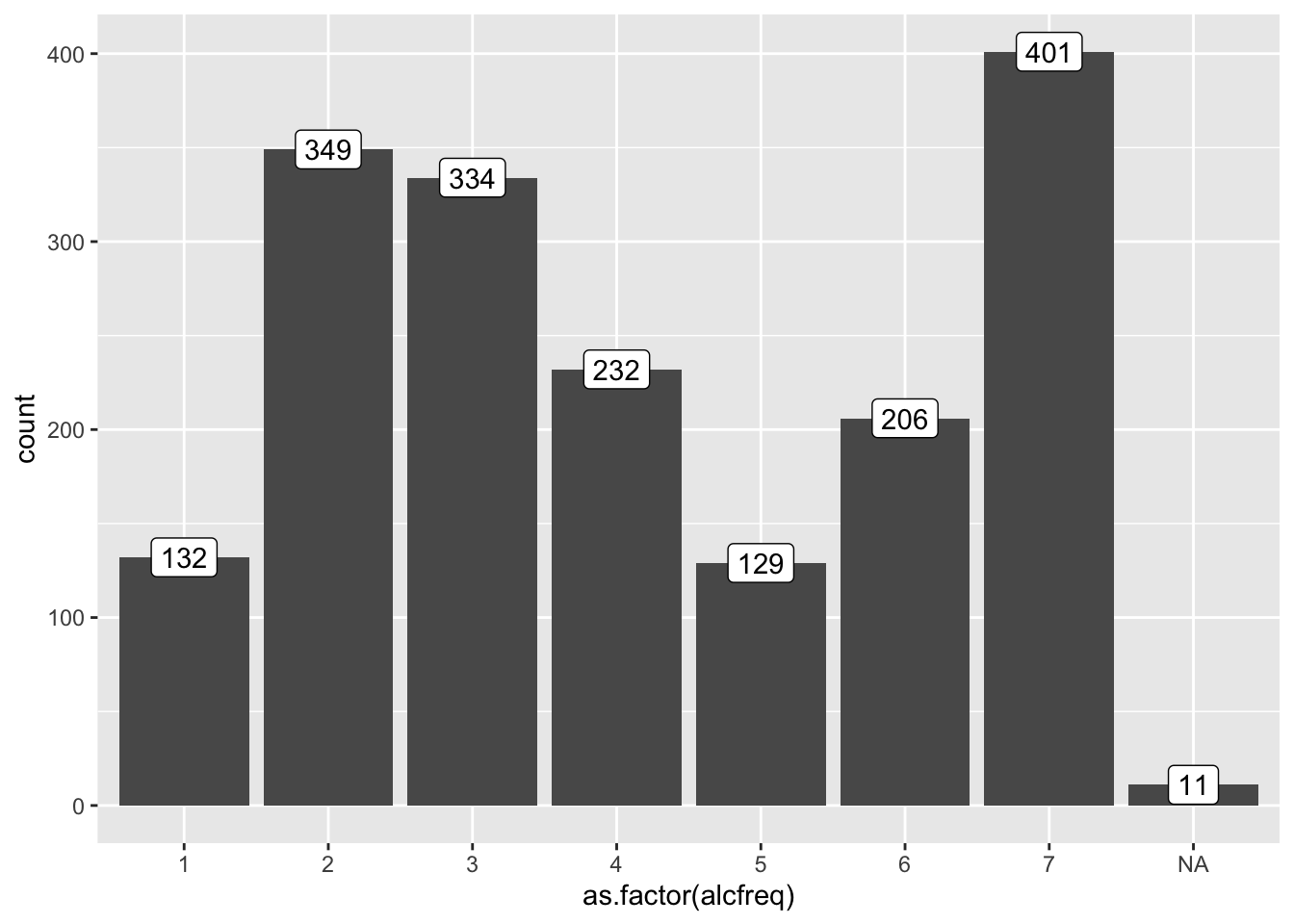
3.2 👉 Самостоятельно - 3
- Покажите на столбиковом графике частоту употребления алкоголя респондентами (
alcfreq). Чтобы избавиться от категорииNA, добавьте строкуscale_x_discrete(na.translate = F)
ggplot(AT, aes(x=as.factor(alcfreq)))+
geom_bar()+
geom_label(stat = "count",
aes(y = stat(count),
label = stat(count))
)
- Разбейте получившиеся колонки по гендеру
ggplot(AT, aes(x=as.factor(alcfreq),
fill = as.factor(gndr)))+
geom_bar(position = "fill")+
scale_x_discrete(na.translate = FALSE)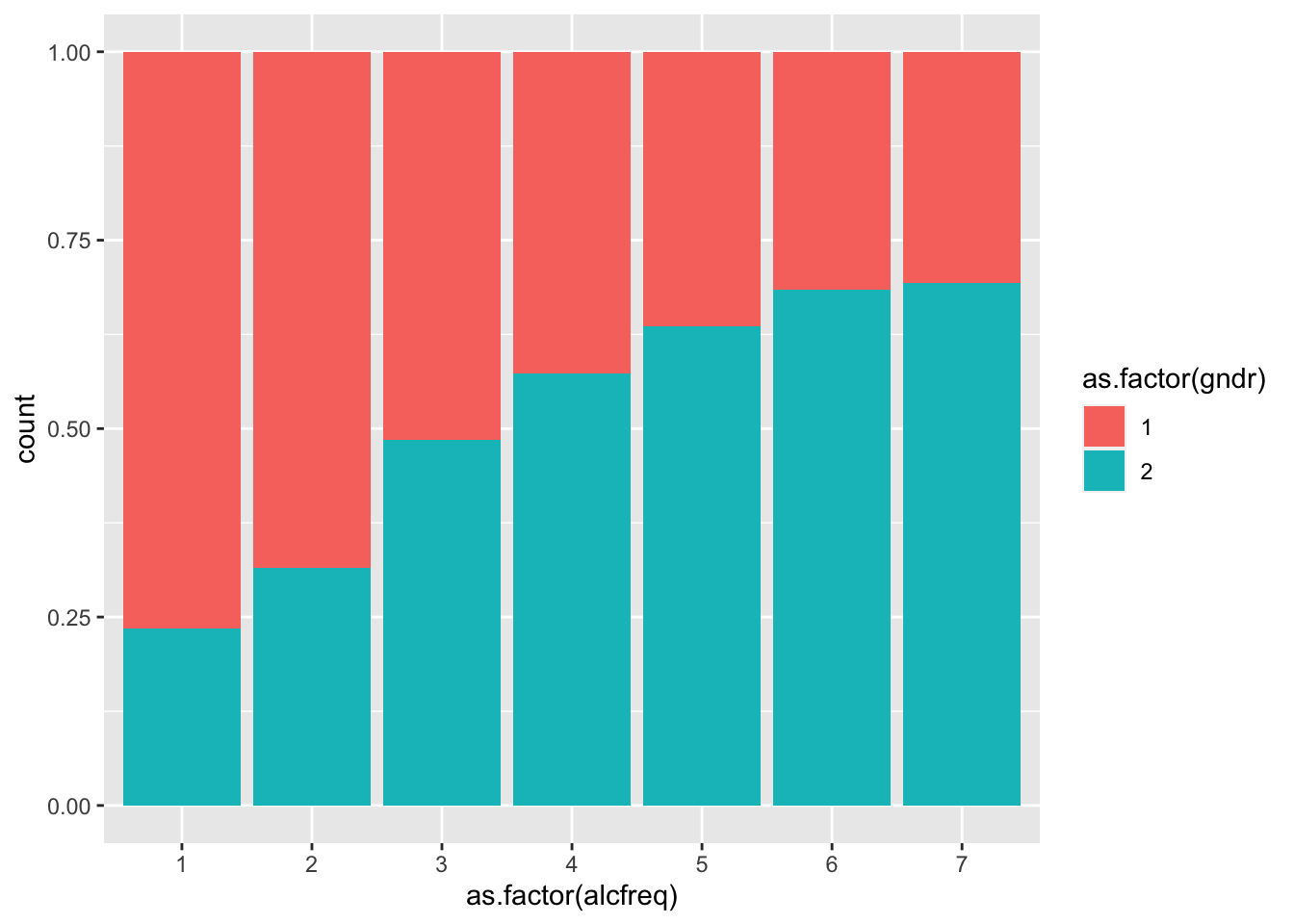
4 Совместное распределение двух интервальных переменных
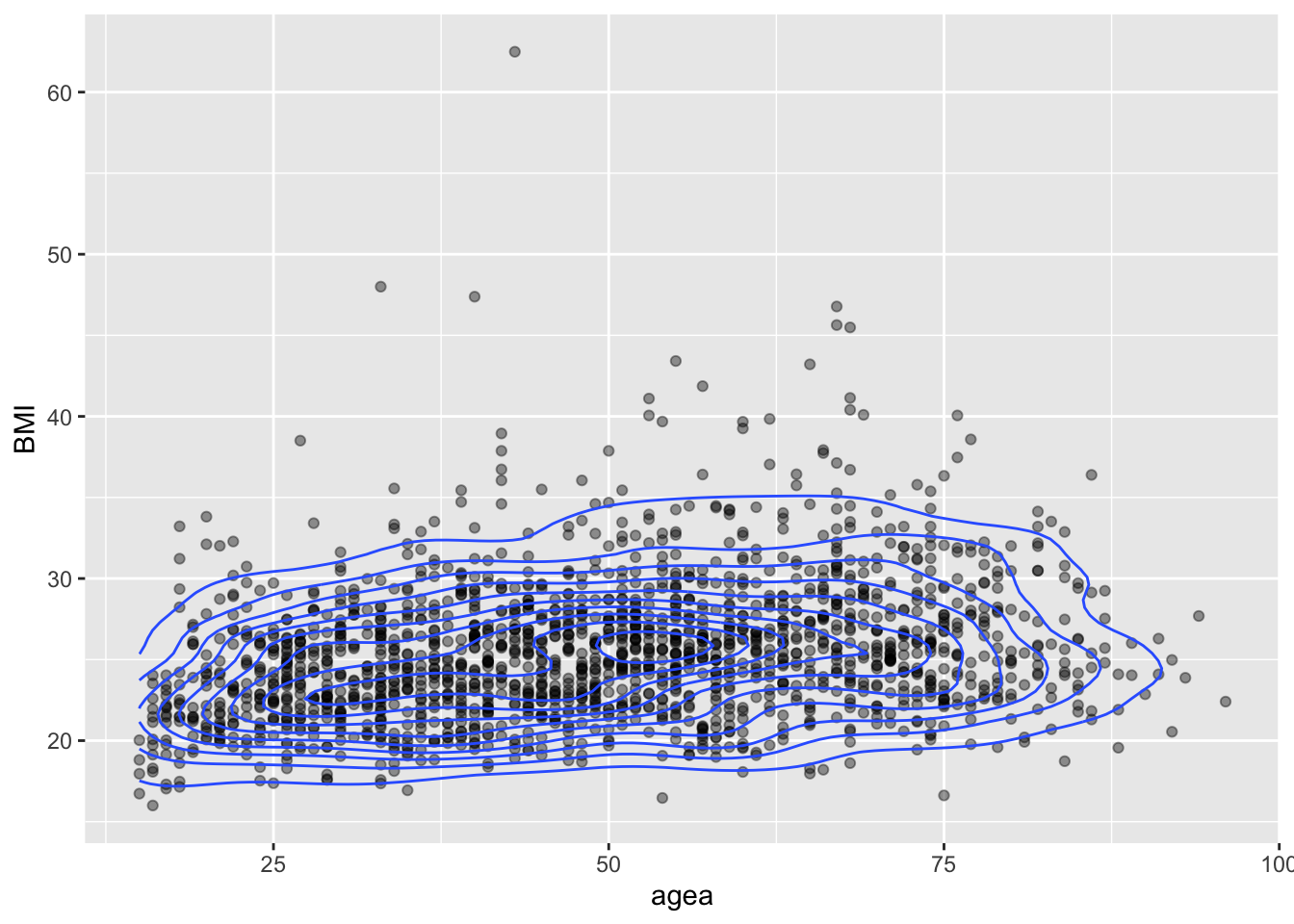
4.0.1 Контурный график
Двухмерный график плотности распределения (см. https://en.wikipedia.org/wiki/Multivariate_kernel_density_estimation). Показывает сгущения в двумерном пространстве.
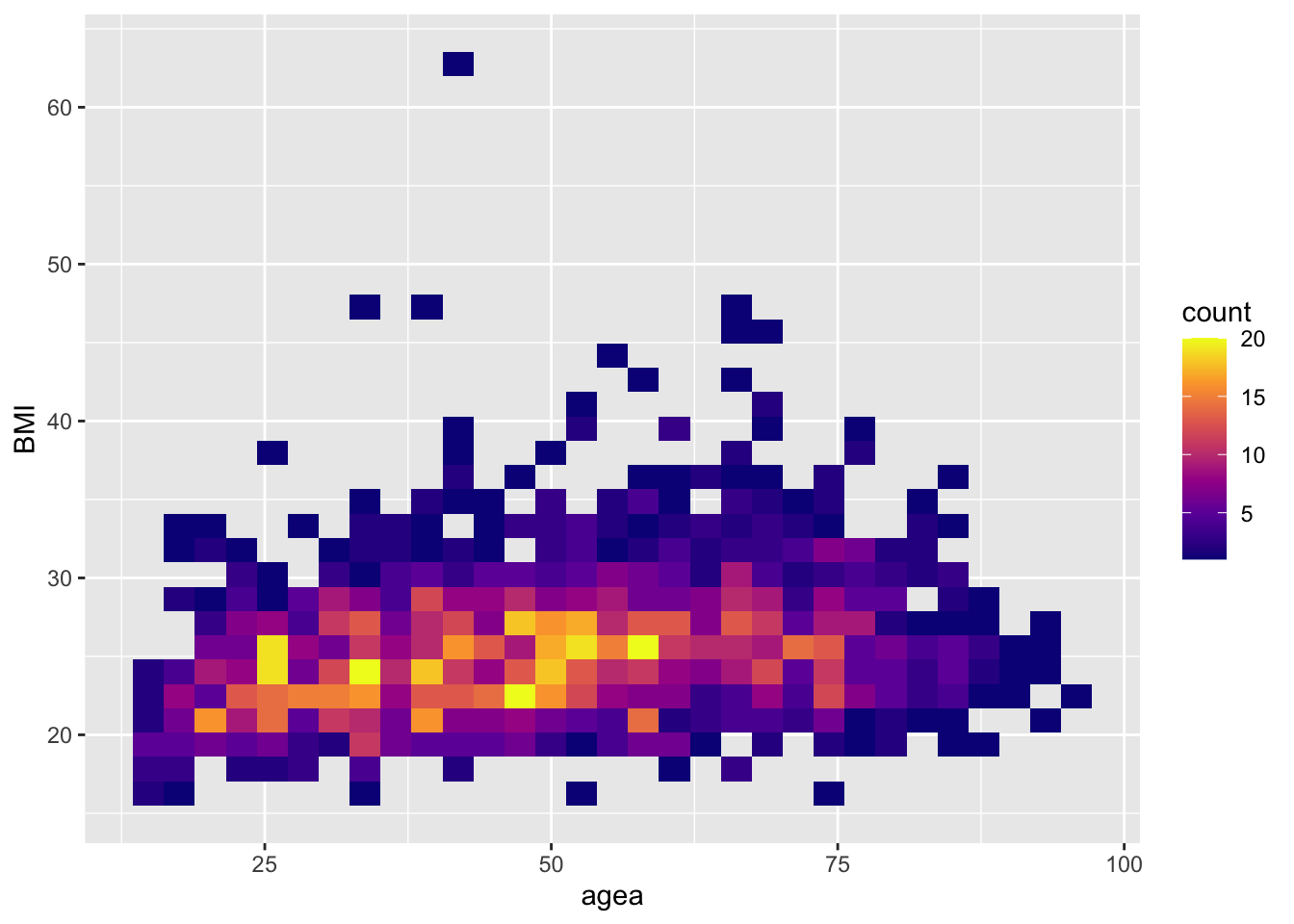
4.0.2 Плиточный график (карта нагрева - heatmap)
Делит систему координат на одинаковые квадраты и подсчитывает сколько случаев попадает в каждый из них.
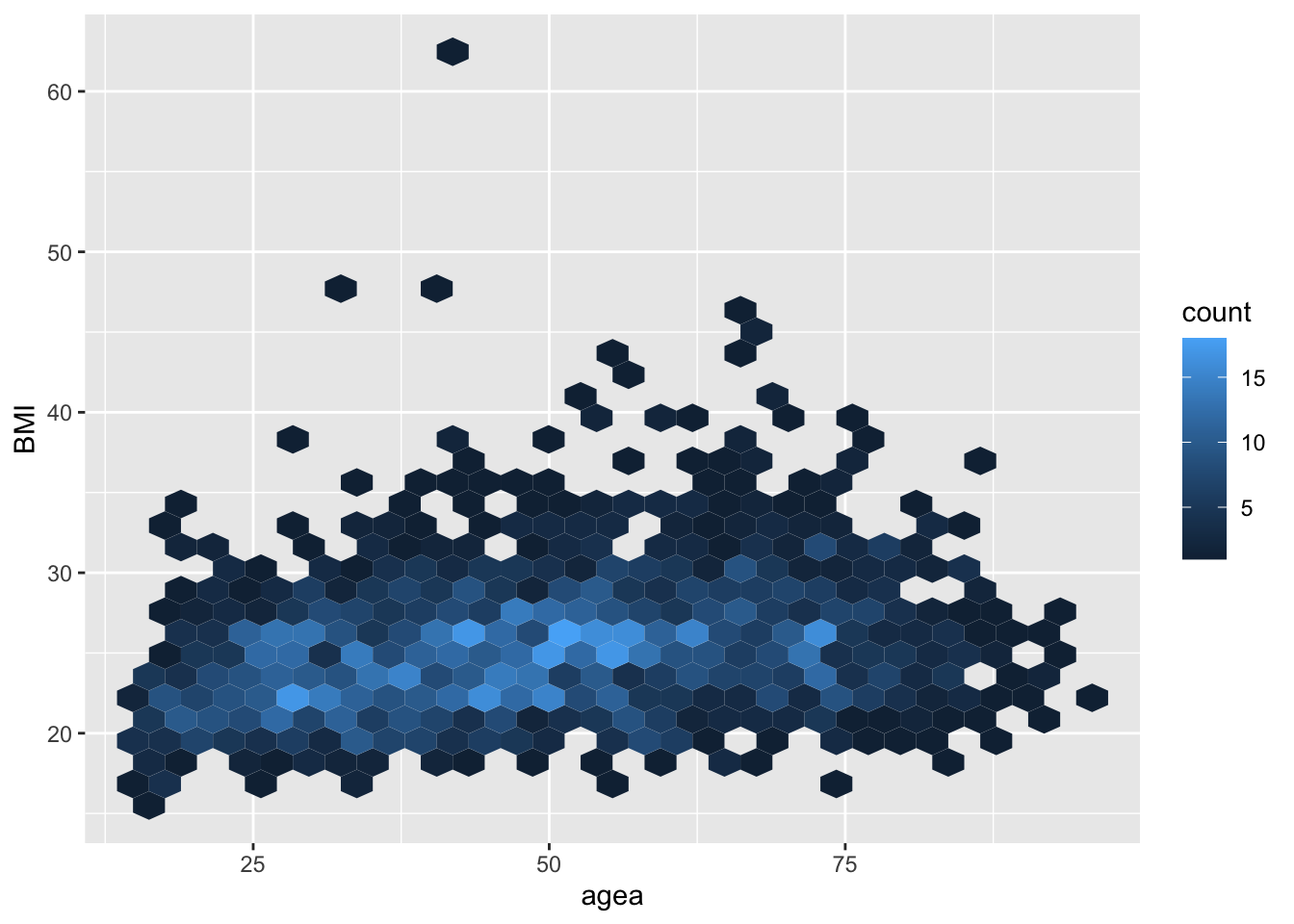
4.0.3 Аналог плиточного графика, но с шестигранниками
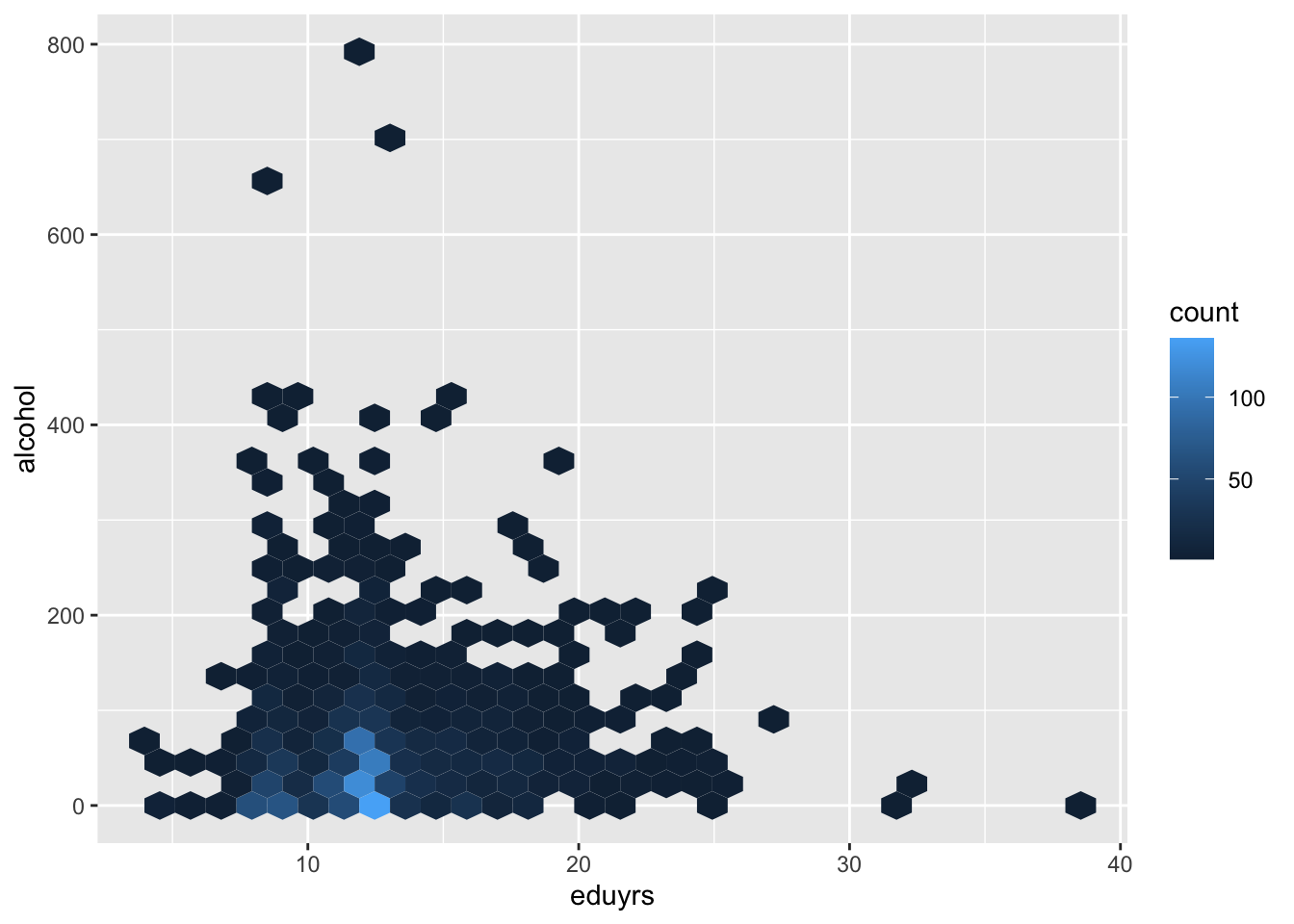
5 Совместное распределение интервальной и категориальной переменной
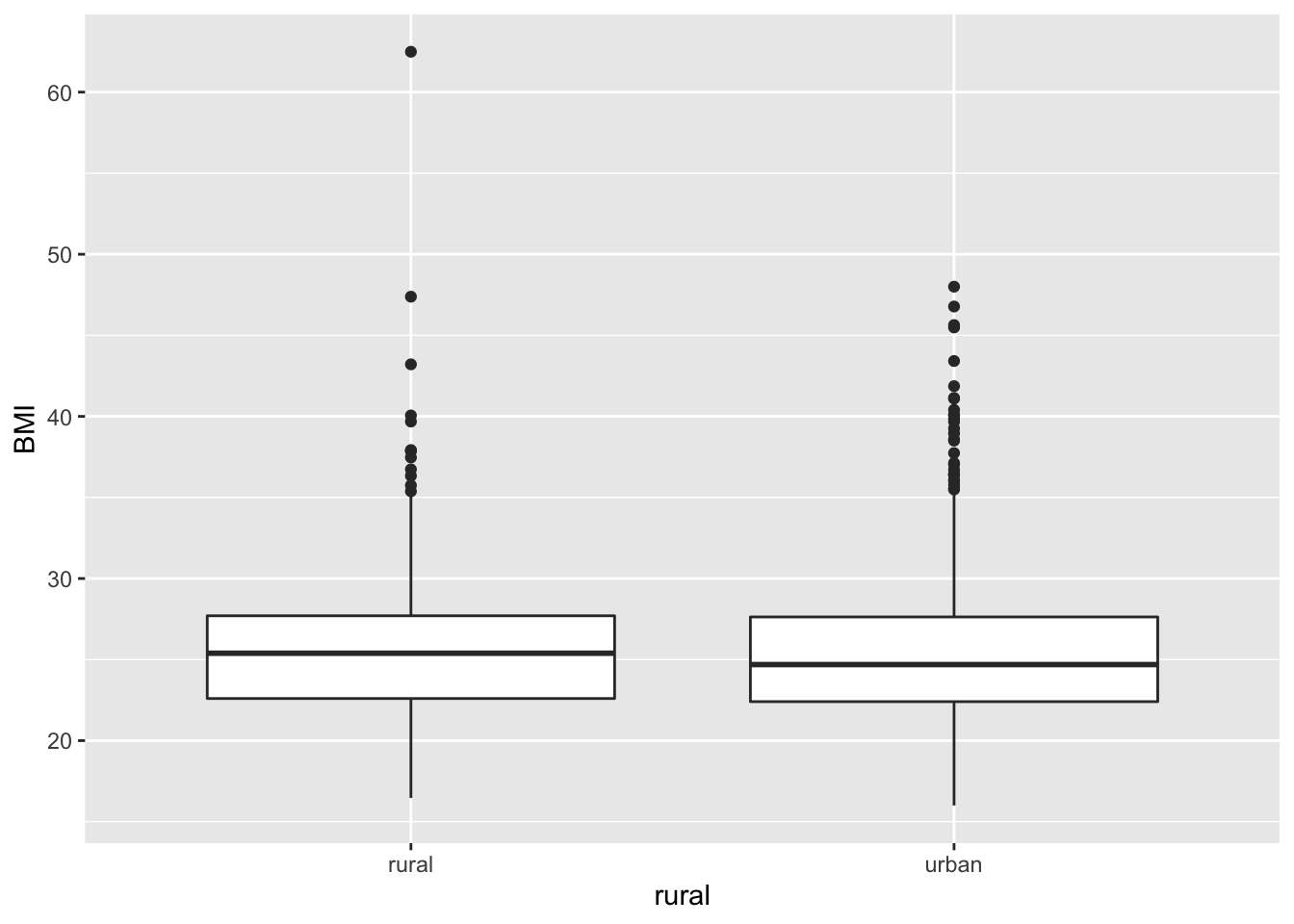
5.0.1 “Коробки с усами” boxplots
Медиана, коробка 25% и 75% квантиль, усы ±1.5 межквартильных разброса.
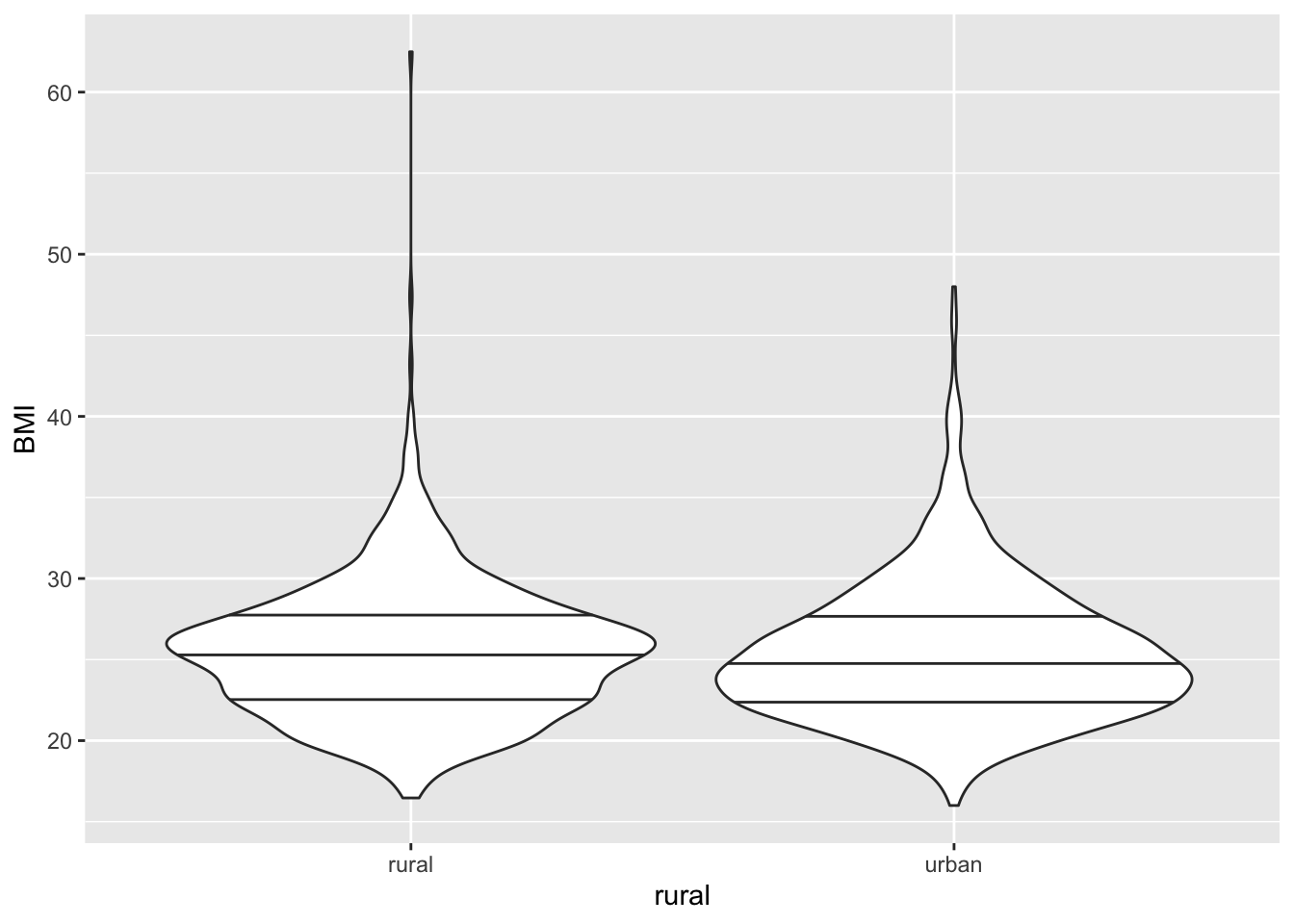
5.0.2 Violin plots
Показывает графики плотности, которые более информативны, чем коробки с усами.
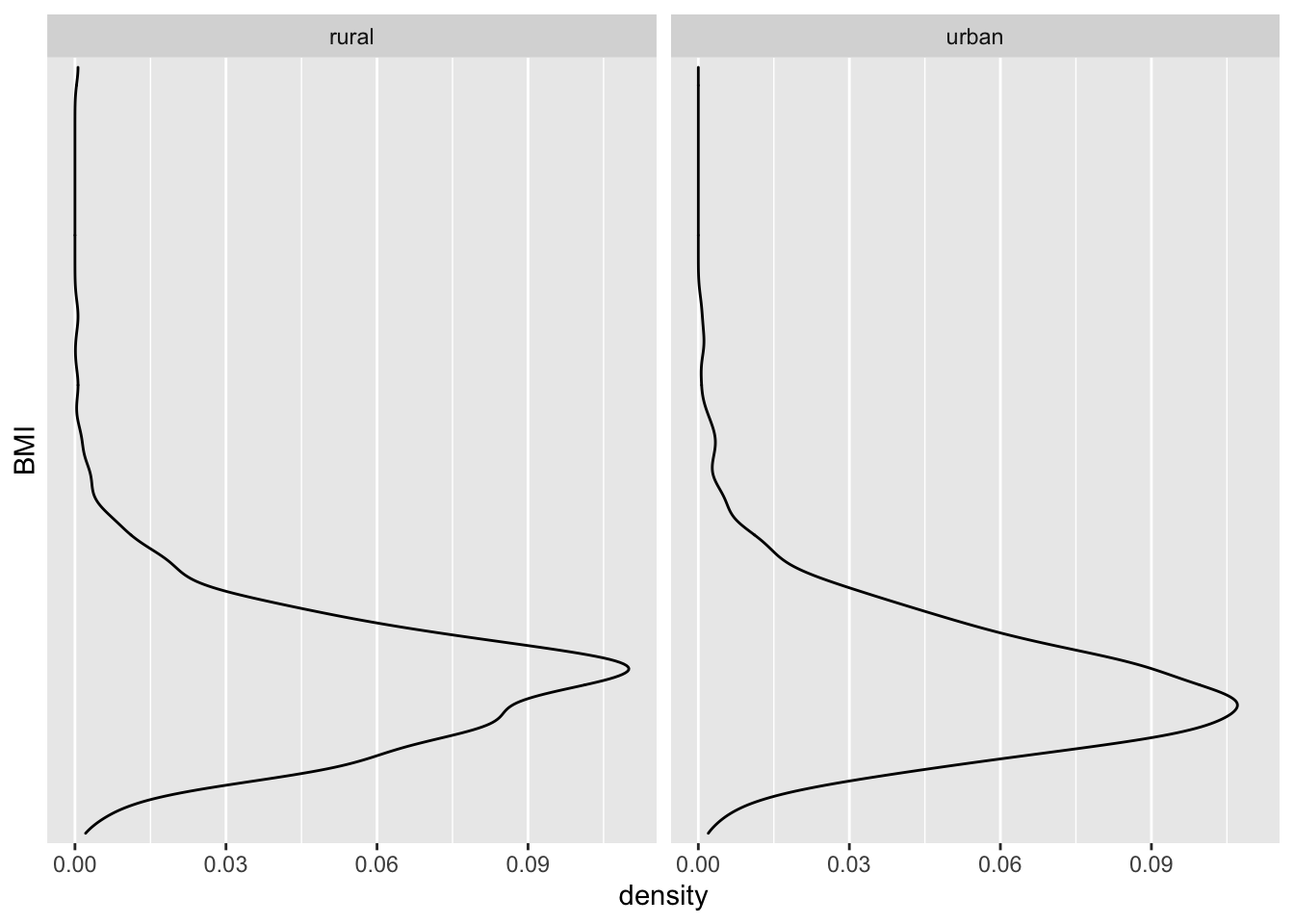
5.1 👉 Самостоятельно - 5
Постройте график совместного распределения переменных alcohol и icpart1 (живет с мужем/женой/партнером == 1).
AT$live_partner <- car::Recode(AT$icpart1,
"1='живет';
2='не живет'",
as.factor = TRUE)
ggplot(AT,
aes(
x = live_partner,
y = alcohol
)
)+
geom_boxplot()+
scale_x_discrete(na.translate = F)+
ylim(0,350)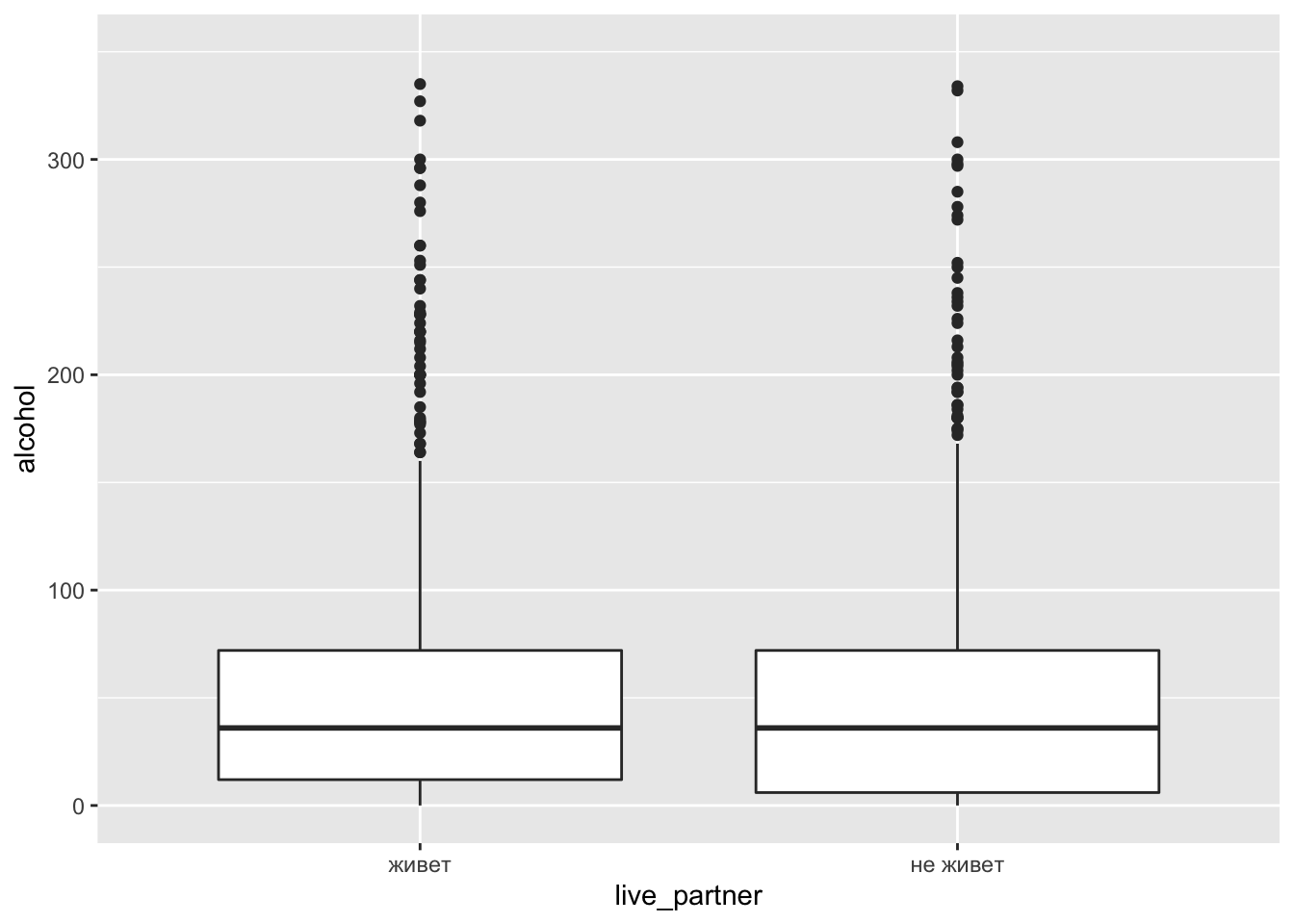
6 Демонстрация связи между двумя непрерывными переменными
6.0.1 Линейная модель (lm)
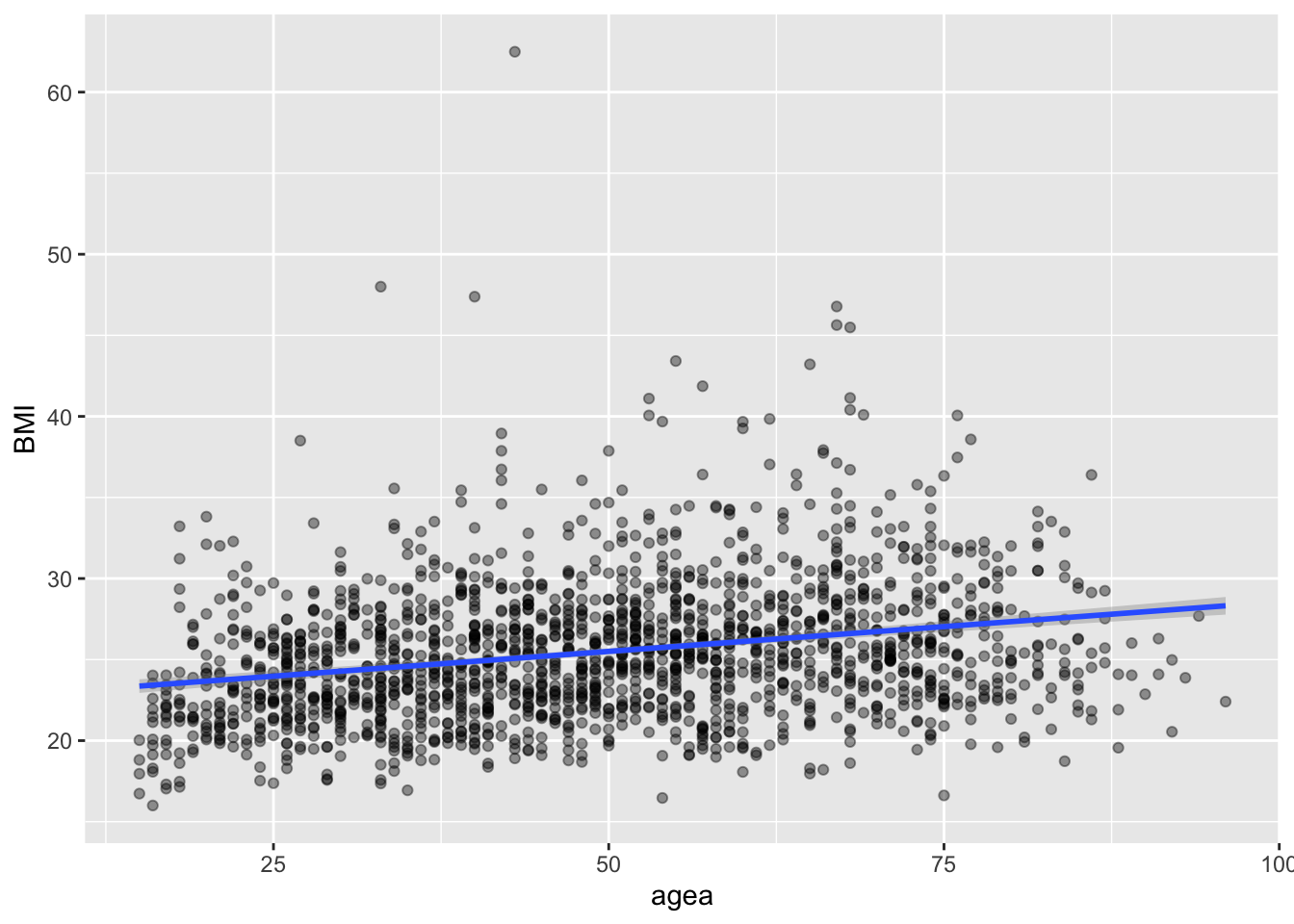
6.0.2 Локально-линейная модель loess
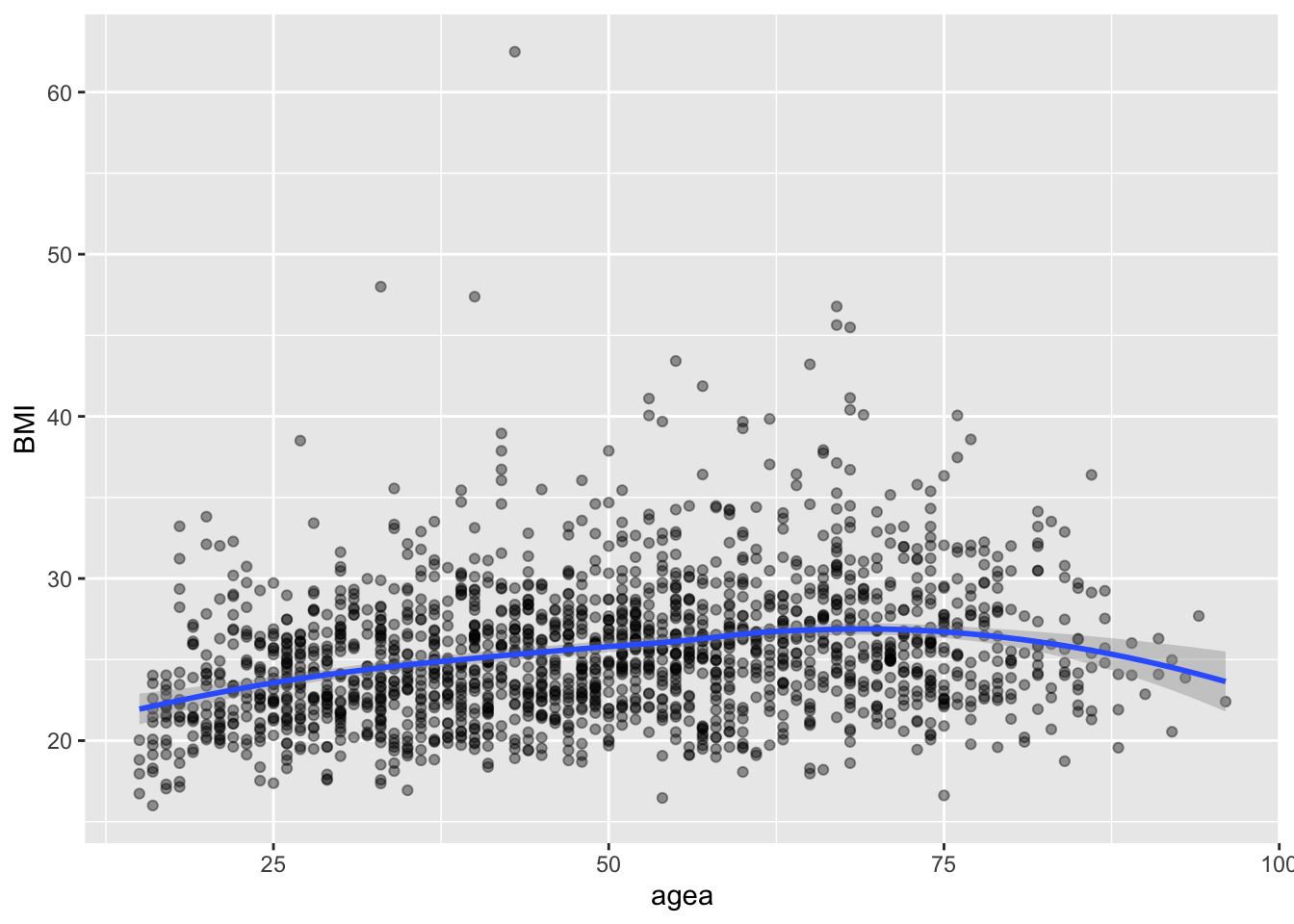
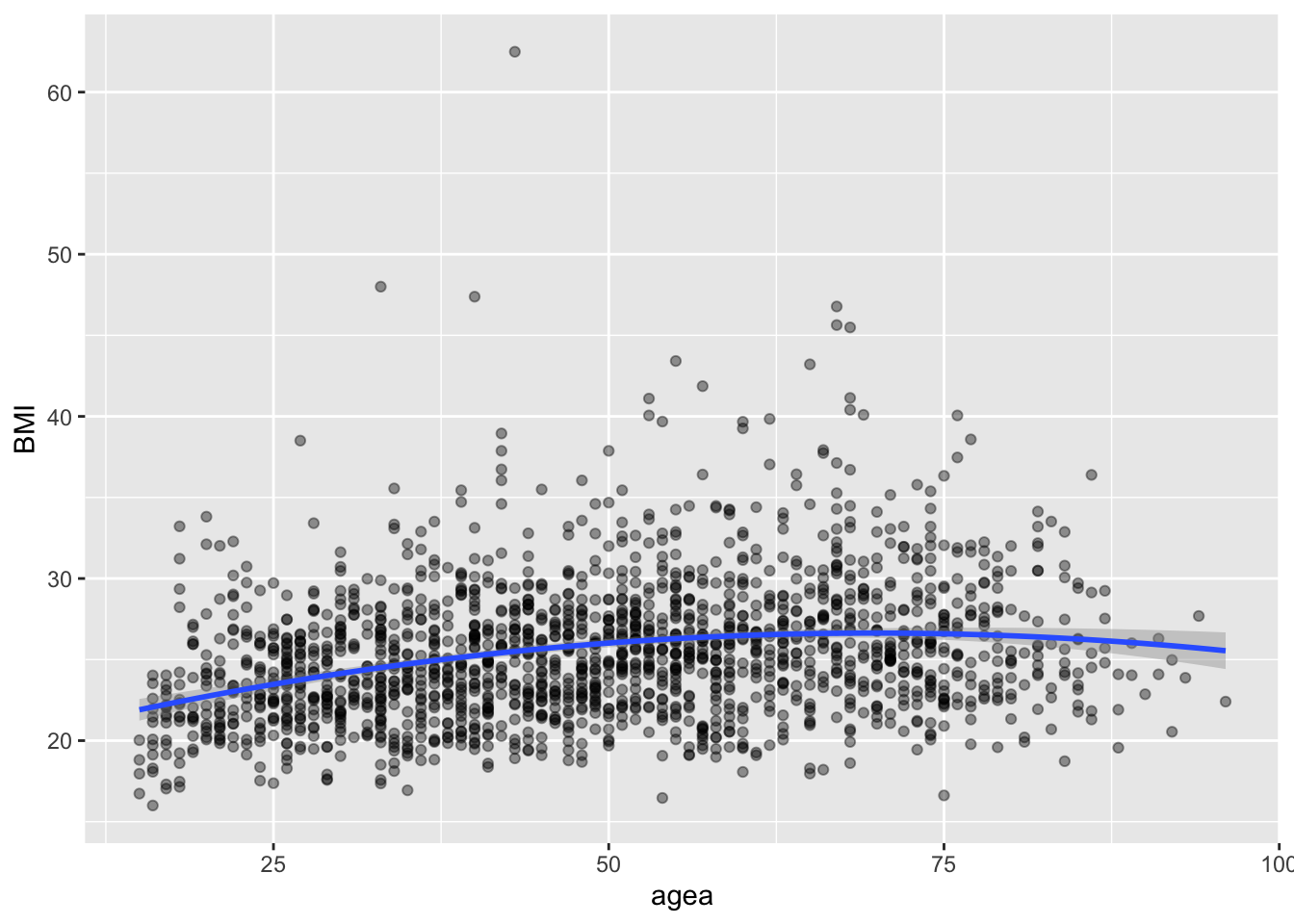
6.0.3 Любая формула для описания кривой связи
ggplot(AT, aes(agea, BMI))+
geom_point(alpha = 0.4)+
geom_smooth(method = "lm",
formula = y ~ x + I(x^2) # здесь указывается форма связи
)
6.1 👉 Самостоятельно - 6
- Покажите графически связь между
средним по странеколичеством употребляемого алкоголя и выкуриваемых сигарет (cgtsday). Предварительно добавьте туда некурящих, указав что они курят 0 сигарет:mydata$cgtsday[mydata$cgtsmke > 2] <- 0. - Используйте
method = 'lm'для отображения линейной связи иmethod ='loess'для нелинейной связи. Уместите обе линии на одном графике. - Выделите две самые курящие страны (цветом, формой маркера или другим способом).
ess7$cgtsday[ess7$cgtsmke > 2] <- 0
d <- aggregate(ess7[, c('alcohol', "cgtsday")],
list(country = ess7$cntry),
mean,
na.rm = T)
d$highlight <- d$country == "HU" | d$country == "AT"
ggplot(d, aes(x = alcohol,
y = cgtsday,
label = country))+
geom_point(aes(color = highlight))+
geom_label(aes(fill = highlight), nudge_x = 4)+
geom_smooth(method ='loess', color = "blue")+
geom_smooth(method ='lm', color = "red")+
scale_color_manual(values = c("black", "red"),
labels = c("the rest", "Top smoking"))+
scale_fill_manual( values = c("grey", "red"),
labels = c("the rest", "Top smoking"))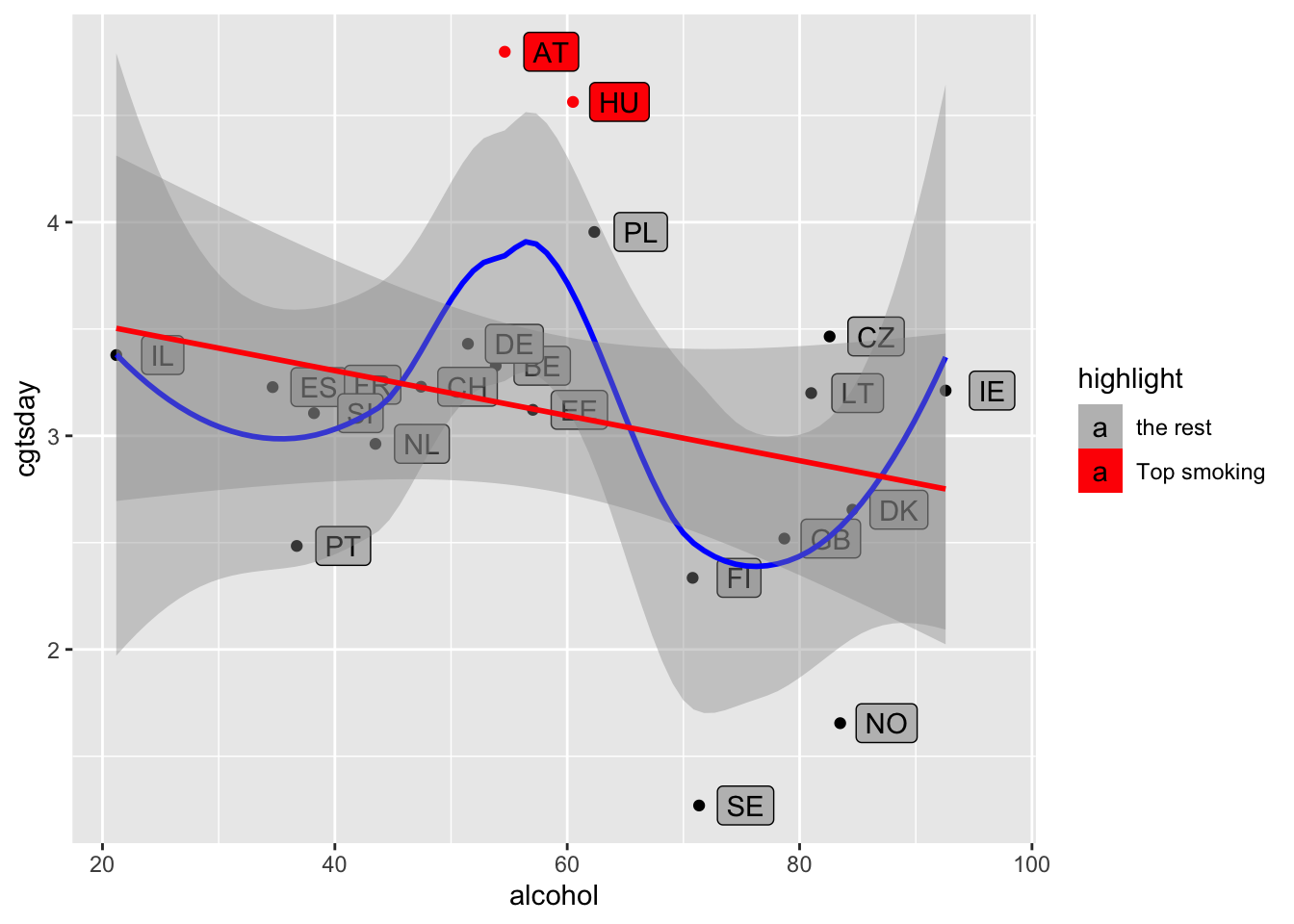
- Экспортируйте этот график в PowerPoint с помощью пакета
esquisse, функция . Для этого сохраните график в объект и используйте функциюggplot_to_ppt()
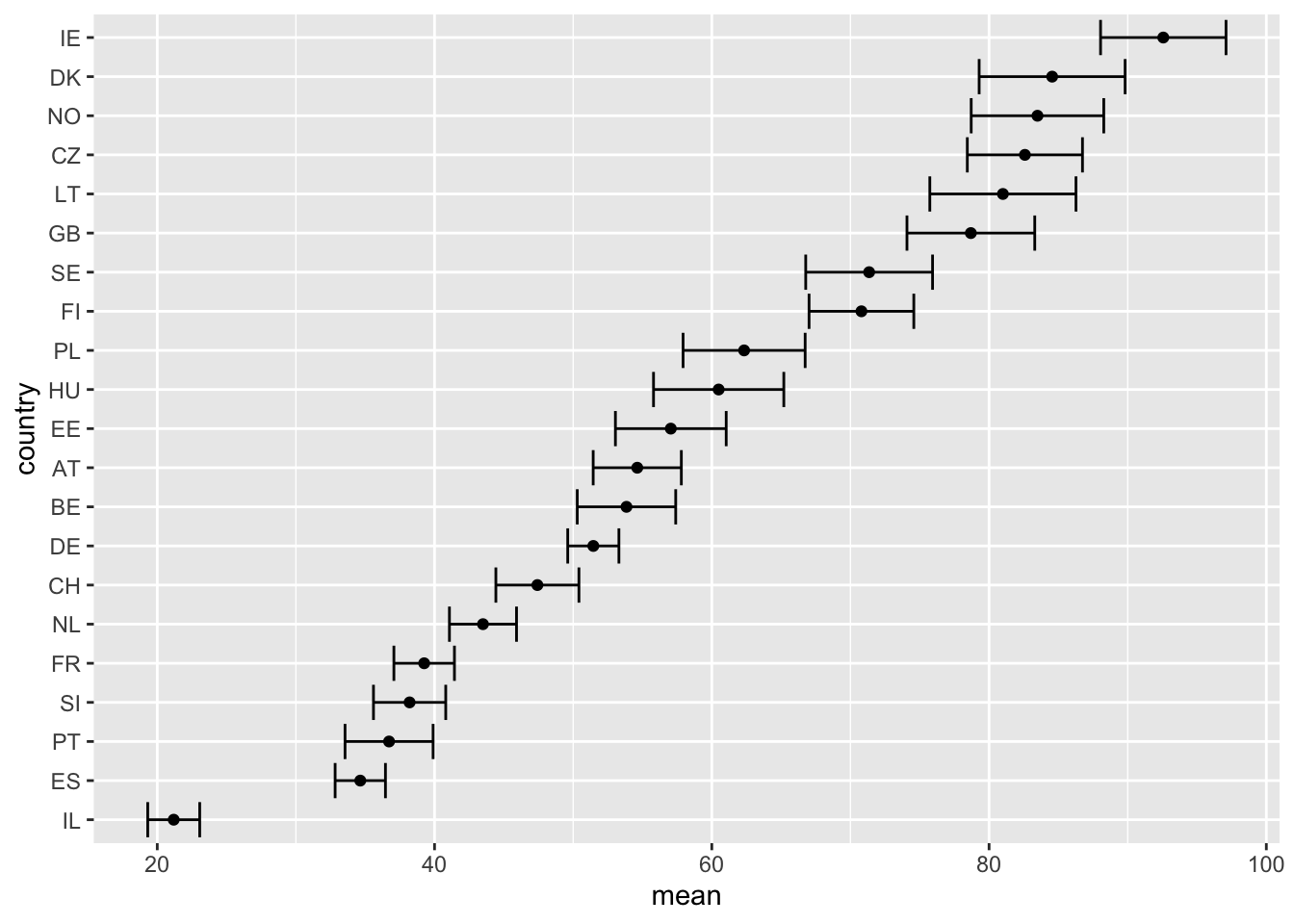
7 Пример подсчета доверительных интервалов
# подсчитываем средние
d.mean <- aggregate(ess7$BMI,
list(country = ess7$cntry),
mean,
na.rm = T)
# подсчитываем стандартные ошибки средних
d.se <- aggregate(ess7$BMI,
list(country = ess7$cntry),
function(x) sd(x, na.rm=T)/sqrt(length(na.omit(x)))
)
# объединяем два массива
d <- merge(d.mean, d.se, by = "country")
# присваиваем понятные имена
names(d) <- c("country", "mean", "se")
# вычисляем доверительные интервалы (1.96 - это критическое значение для 95% доверительного интервала)
d$ci.upper <- d$mean + d$se * 1.96
d$ci.lower <- d$mean - d$se * 1.96
# упорядочиваем уровни в переменной country
d$country <- reorder(d$country, d$mean)
# строим график
ggplot(d, aes( y = country ,
x = mean,
xmin = ci.lower,
xmax = ci.upper,
label = round(mean,1)))+
geom_errorbarh()+ # этот геом добавит горизонтальные линии, соответствующие доверительным интервалам
geom_point()+
geom_text(nudge_y=.4, size = 2.5)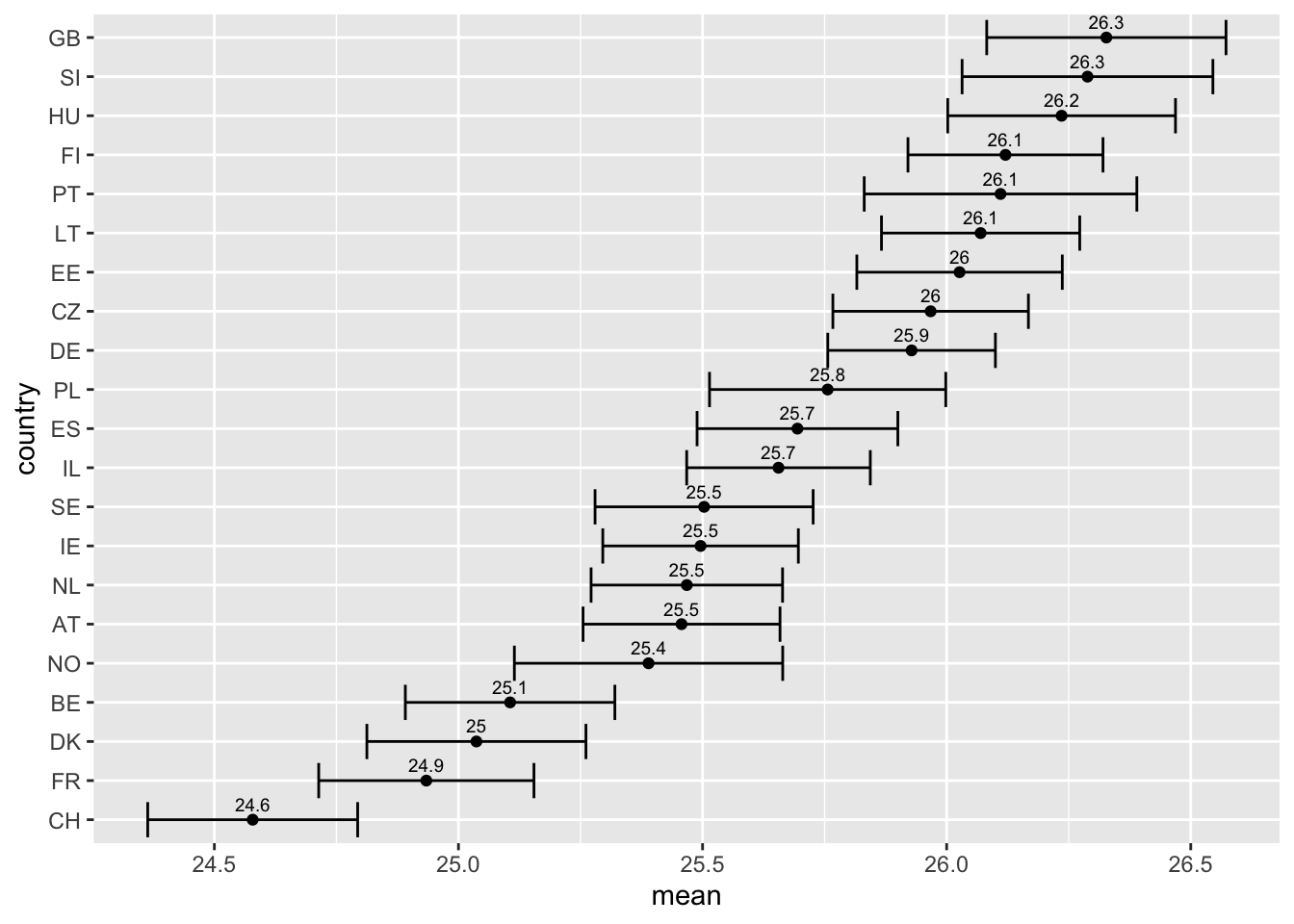
7.1 👉 Самостоятельно - 7
Постройте график среднего количества выпитого, с доверительными интервалами средних.
# подсчитываем средние
d.mean <- aggregate(ess7$alcohol,
list(country = ess7$cntry),
mean,
na.rm = T)
# подсчитываем стандартные ошибки средних
d.se <- aggregate(ess7$alcohol,
list(country = ess7$cntry),
function(x) sd(x, na.rm=T)/sqrt(length(na.omit(x)))
)
# объединяем два массива
d <- merge(d.mean, d.se, by = "country")
# присваиваем понятные имена
names(d) <- c("country", "mean", "se")
# вычисляем доверительные интервалы (1.96 - это критическое значение для 95% доверительного интервала)
d$ci.upper <- d$mean + d$se * 1.96
d$ci.lower <- d$mean - d$se * 1.96
# упорядочиваем уровни в переменной country
d$country <- reorder(d$country, d$mean)
# строим график
ggplot(d, aes( y = country ,
x = mean,
xmin = ci.lower,
xmax = ci.upper))+
geom_errorbarh()+ # этот геом добавить горизонатльные линии, соответствующие доверительным интервалам
geom_point()